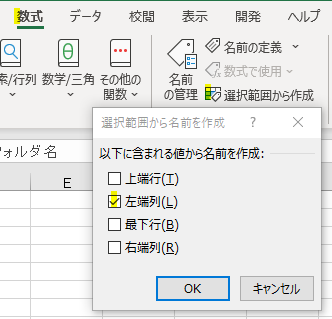
Power Queryの便利な点は、普段から使い慣れたエクセルをAccessのようなデータベースとして活用できる点です。このページを訪問して頂いた方の中にもAccessは細かなルールが多くて不便と感じた方もいらっしゃったと思います。
Power Queryは自動で、Accessの不便な点を補ってくれる機能があります。そのかわり、エラーが出やすい箇所があります
このエラーはPower Queryの2つの特徴と深く結びついています
Power Queryの2つの特徴について解説しながら、「列名変更」に関するエラーの発生を防ぐ方法について解説します
エラーの発生を防ぐ方法を理解した時には、「データ形式」も含めてPower Queryへの理解が一段と深まっているはずです!
ところで、
エクセルとAccessの違いとは何でしょう??
エクセルはあくまで表計算ソフトです
Accessはデータベースソフトです
この2つの違いを、別な言い方で表現すると「データの構造化」ということになります
こちらが、Power Queryの特徴の1つ目の話しです
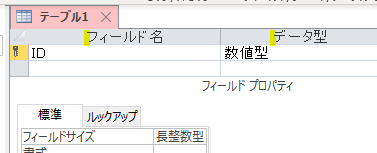
Accessでは、いきなりデータから入力はできないようになっています
上の画像のように「データを入力する箱」をフィールド毎(エクセルでは列毎)に「フィールド名/見出し」「データ型」を設定しなくてはいけません
つまり、予め入力するデータの箱を「構造化」しておくわけです
今回の解説では、上の画像についてはこれ以上は深入りしませんが、上で前述した「データの構造化」を意識して、以降の記事を読み進めてみてください!!
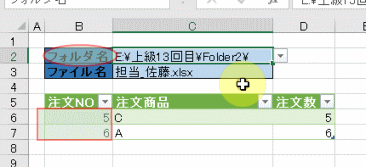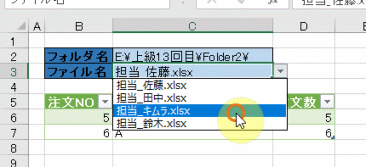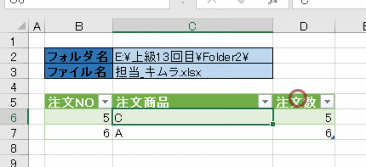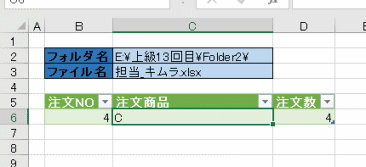
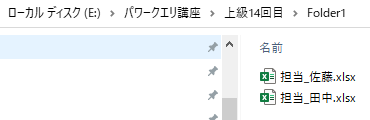
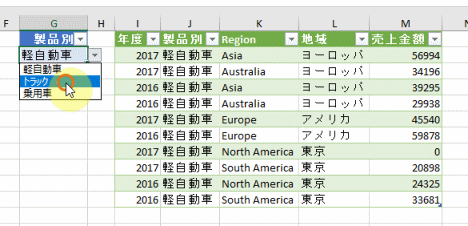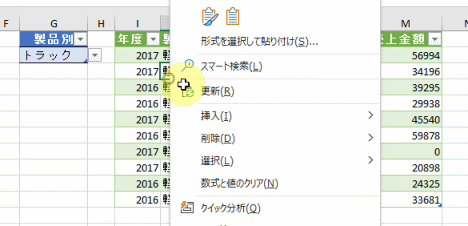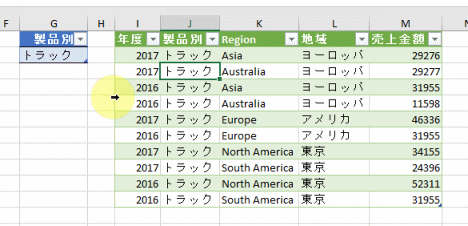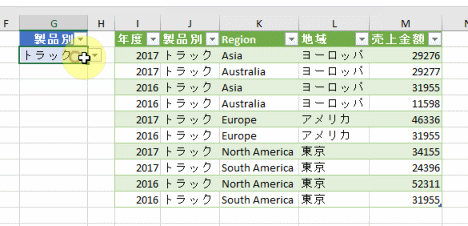
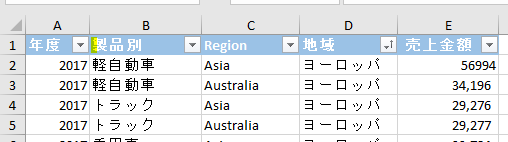
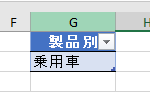
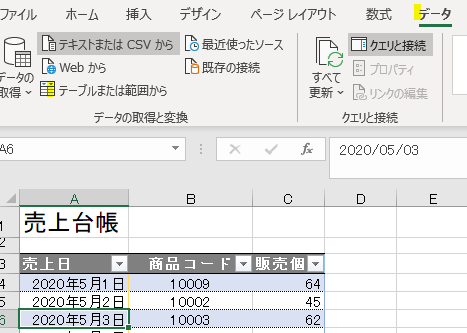
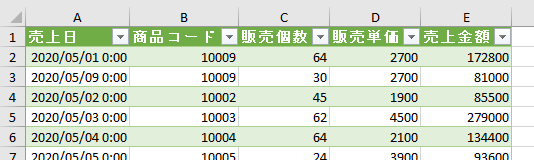
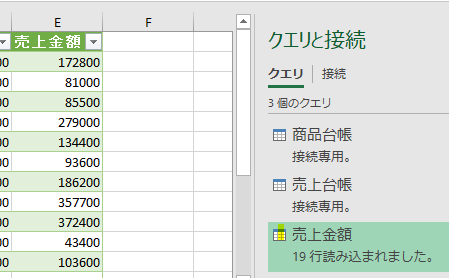
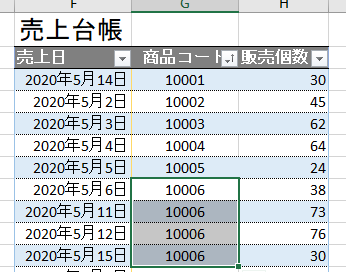
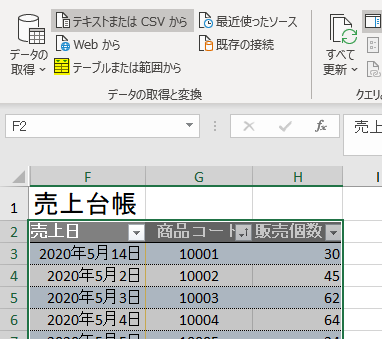
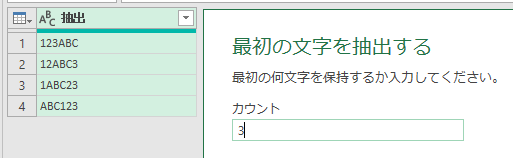
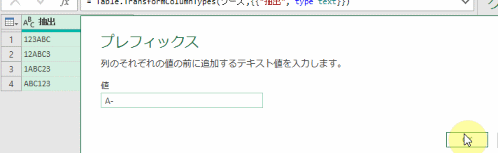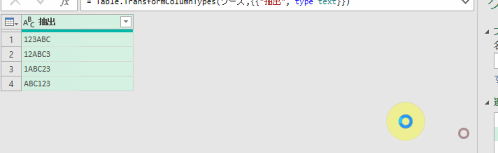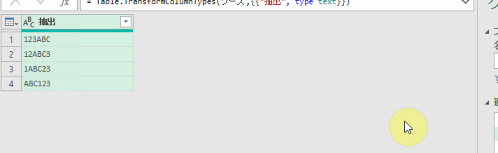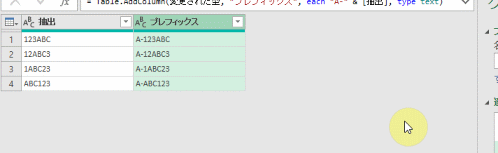
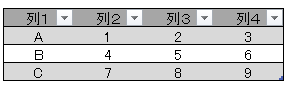
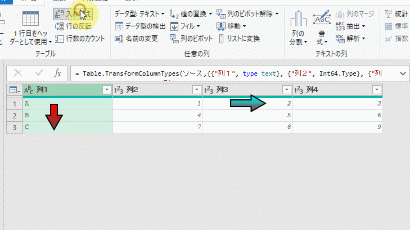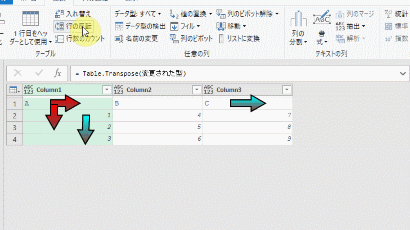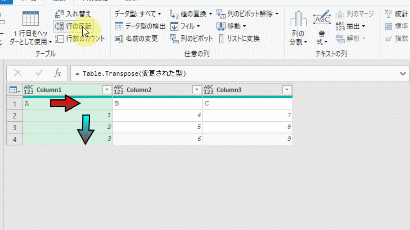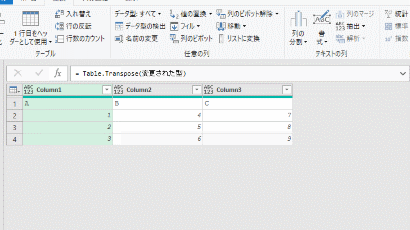
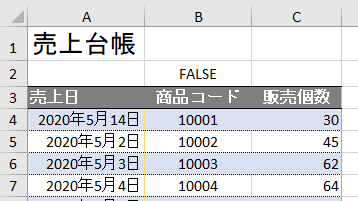
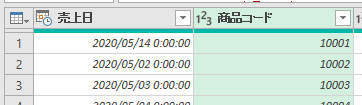
今回、解説に使用するデータは次の画像のデータです
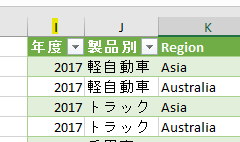
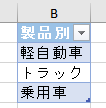
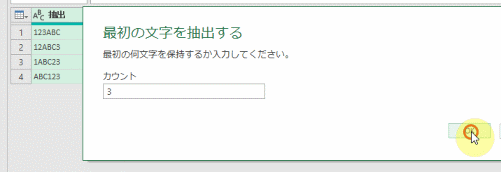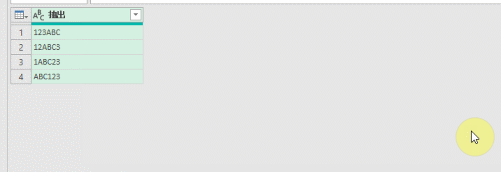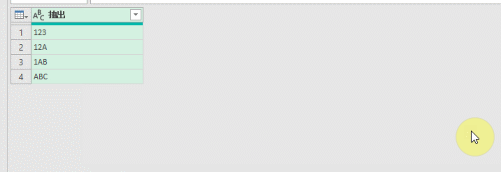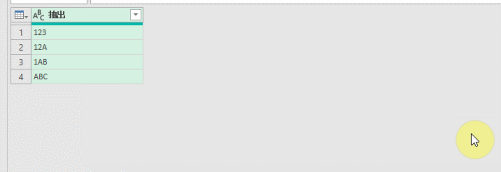
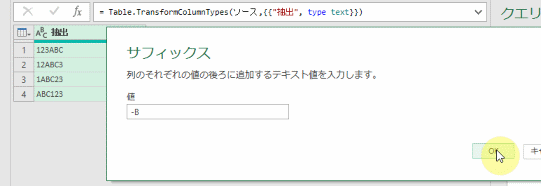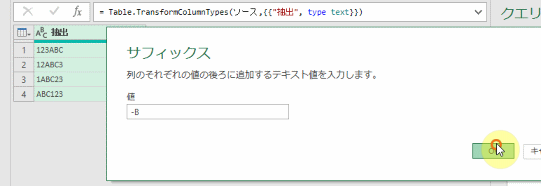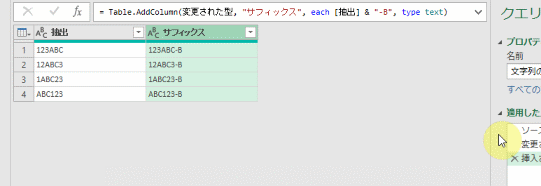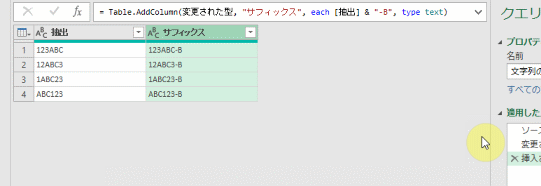
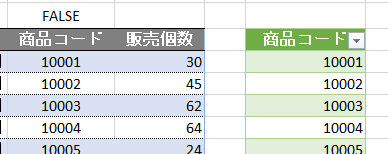
こちらの3列(売上日、商品コード、販売個数)からなるテーブルデータから、下の画像のように商品コードの1列を抽出するクエリを作成しておきます
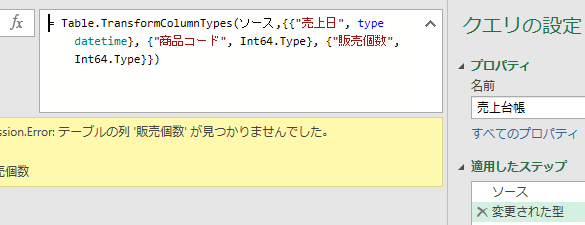
そして、元のテーブルデータの「販売個数」の列名を変えます
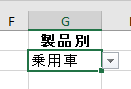
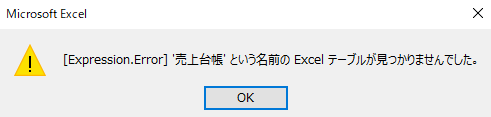
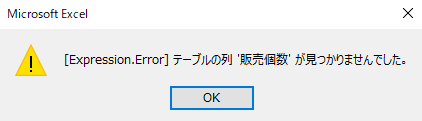
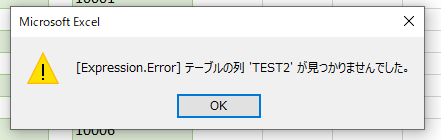
すると、「商品コード」のみを抽出するクエリを更新するとエラーになります
エラーの中味を見てみると、抽出する「商品コード」とは関係ない列の「名前変更」によりエラーが発生しています
実は、このエラーは前述の「データの構造化」が深く関係しています
では、こちらのエラーを回避する方法を以下、2パターンで解説します
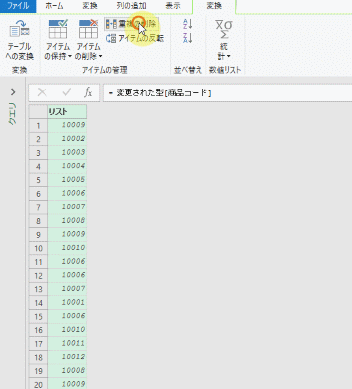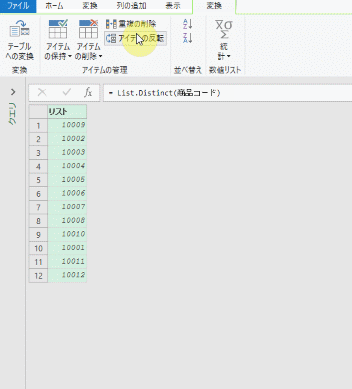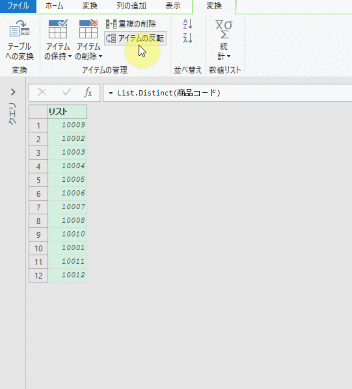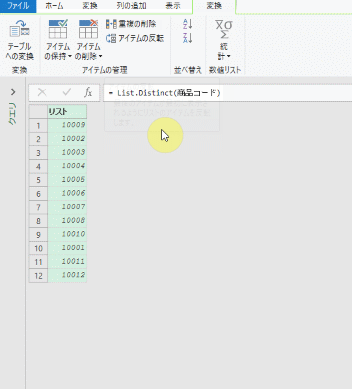
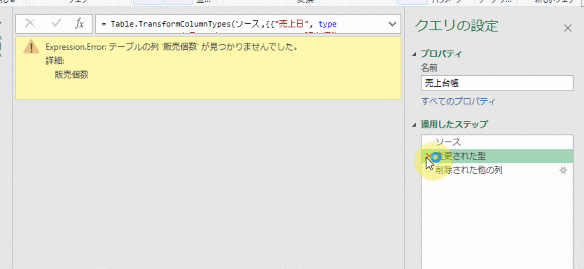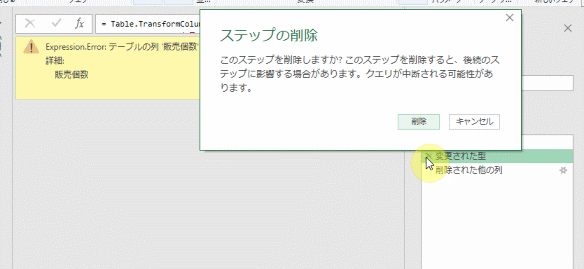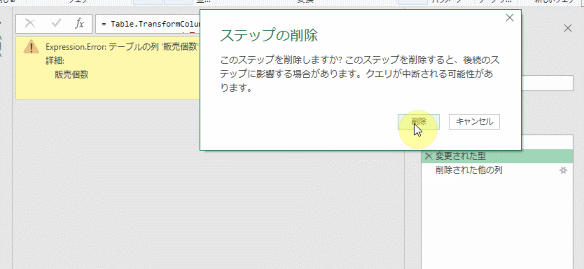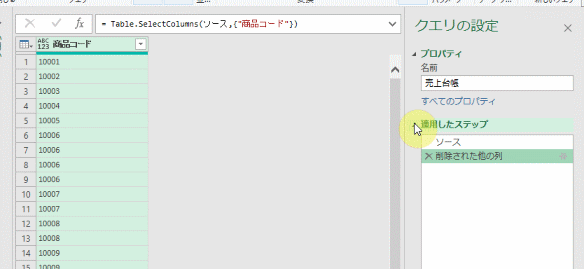
1.ステップ「変更された型」の削除
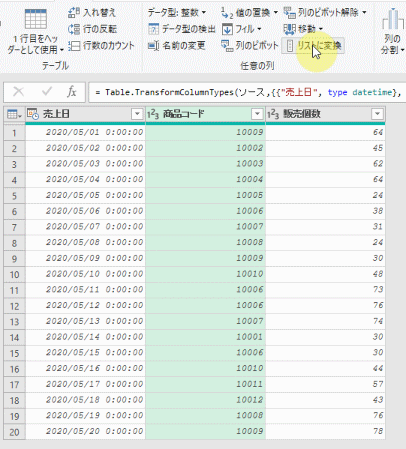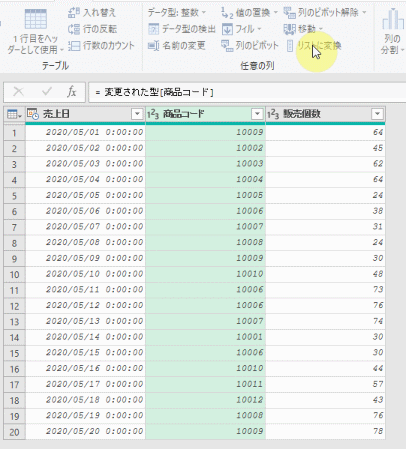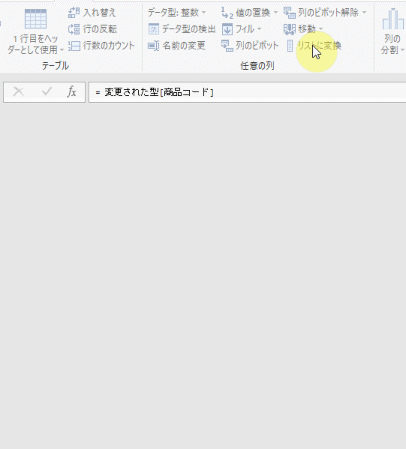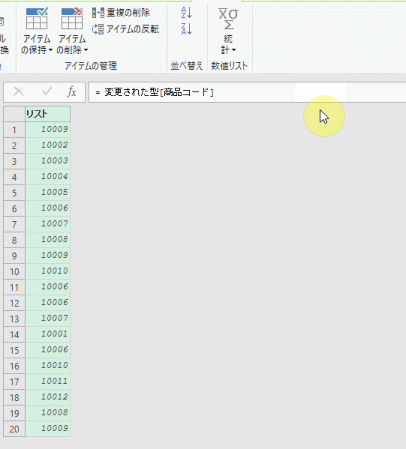
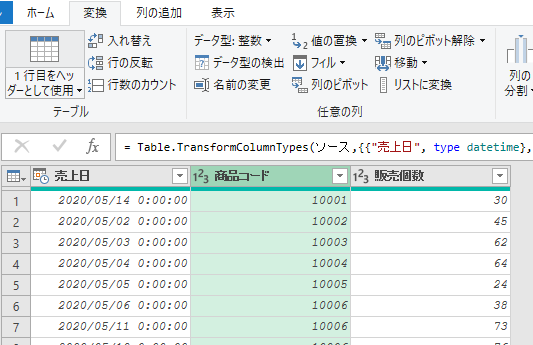
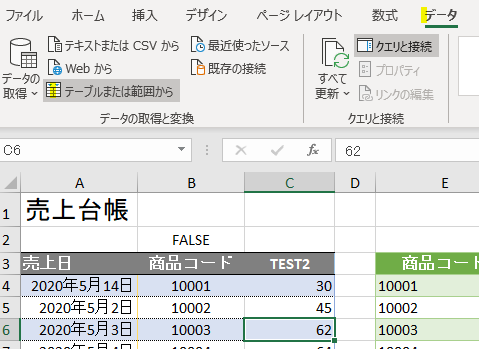
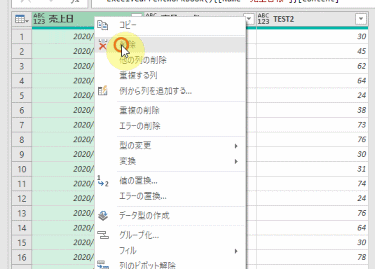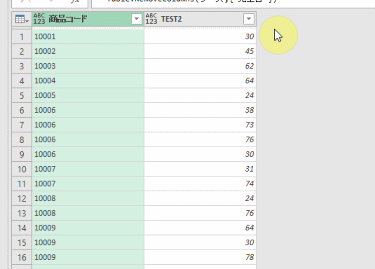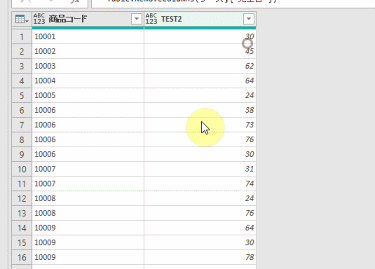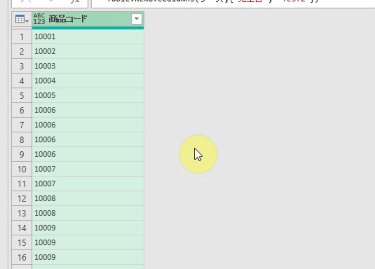
まずは、前述のクエリの中味をPower Queryエディタ(以降、エディタ)で見てみます
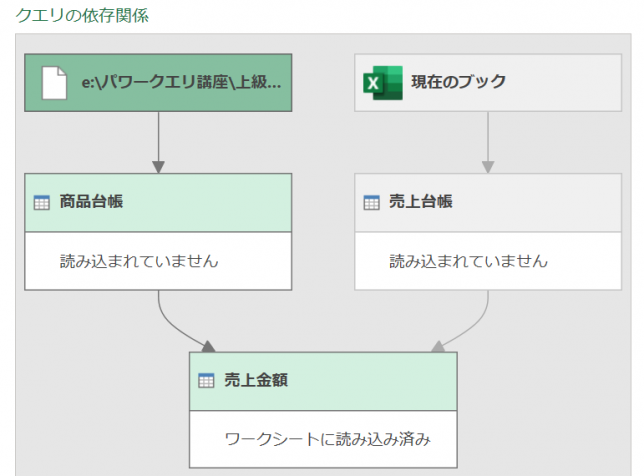
適用したステップは3つあります
こちらの3つのステップを、上から順に各ステップの「数式」を見てみます
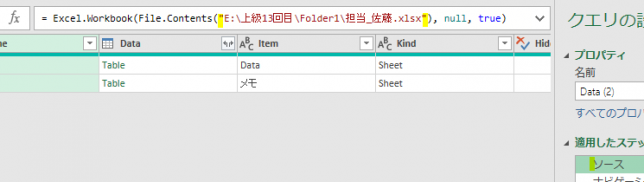
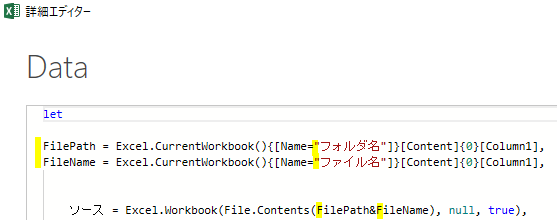
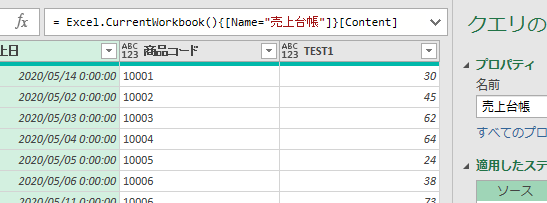
①ソース
こちらは、ファイル内の「売上台帳」テーブルをデータソースとして読み込んでいるのが分かります
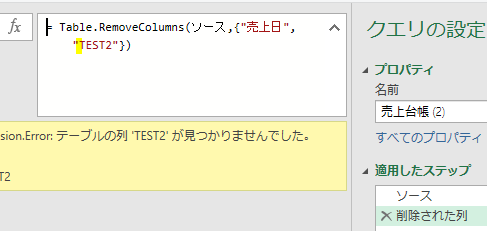
②変更された型
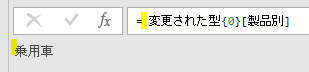
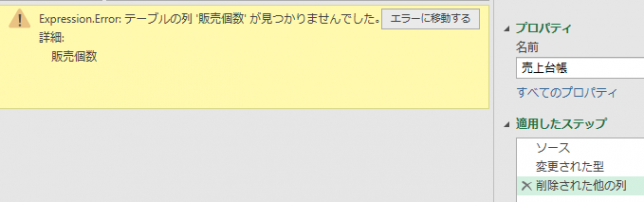
こちらのステップでエラーが発生しているのが、よく分かります
こちらの数式に含まれる「販売個数」は、既に名前が変更されているのでエラーが発生しています
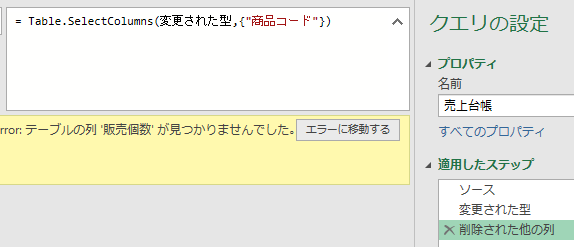
③削除された他の列
こちらのステップで「商品コード」列のみを抽出しています
実際には、次の画像のように「商品コード」以外の列を削除してステップが作成されています
①~③のステップの中味を確認したところで、エラー原因となった②のステップを削除してみます
すると、エラーは消えます
仮に元の列名が「販売個数」の列名を、再度変更してもエラーは発生しません
これで、列名の変更でエラーが発生しないクエリに変更できました
ところで、
今回のエラー発生の原因となった「変更された型」のステップとはなんでしょうか?
エディタを開く時には、「変更された型」のステップは自動挿入されています
このステップは記事の冒頭で前述したPower Queryの1つ目の特徴である「データの構造化」と深くかかわっています
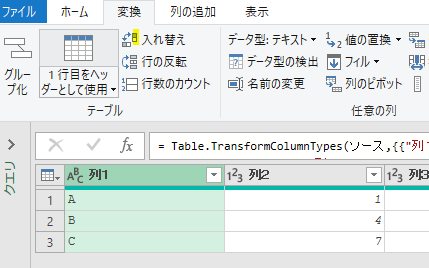
試しに下の画像のように、最初からクエリを作成してみます
開いたエディの中味を見ると、「変更された型」が前述のように自動追加されています
そして、各列も自動で「型式」が変更されています
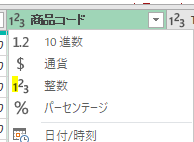
例えば、商品コードの型式は元々は「文字列」でしたが、下の図のように「123」マークの「整数型式」に自動変換されています
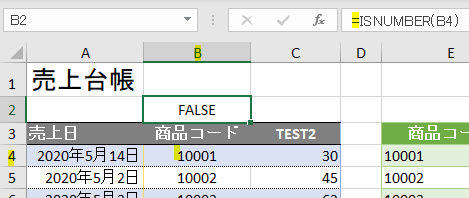
下の図のように元のデータにて、数字かどうかを判定する数式「ISNUMBER」で判定するとFALSEになり、「文字列」だったことがよく分かります
記事の冒頭で前述したように、エクセルはあくまで表計算ソフトです
表計算ソフト内にあるデータは、データベースとしては構造化されていません
Power Queryでは、Accessとは違い、自動でエディタ内にて「構造化」の設定を行ってくれているのです
ちなみに、AccessのファイルをPower Queryで読み込むと「変更された型」のステップは発生しません
AccessファイルをPower Queryで読み込む方法は過去の記事で紹介していますので、興味のある方は試してみてください
話をPower Queryの「構造化」に戻します
「構造化」は元データの全ての列に対して設定を行うので、エディタ内で削除した列も設定の対象です
しかも「構造化」は元の列名に対して行われます
ですので、一見、クエリに関係ない列の「名前の変更」が影響するのです
但し、「商品コード」が文字列から「整数」に変換されたように、常に正しく「構造化」が行われるわけではないので注意が必要です
自動で変更された型を変更する場合には、下のGIF画像の箇所で調整を行います
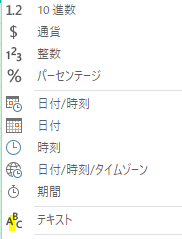
下の図のように「文字列」は「テキスト」となっている点に注意してください
上の図の詳細な内容については、一覧でMicrosoft社のHP内で紹介されています
さて、
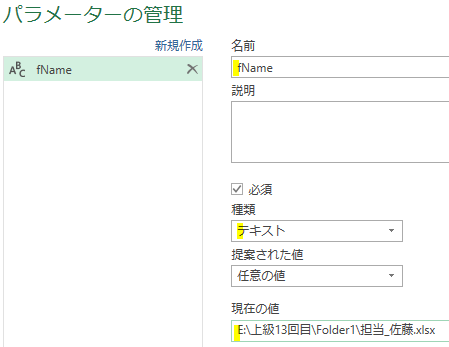
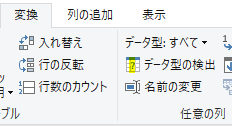
エラー発生の対策をしたクエリからは「変更された型」のステップは削除されていますが、こちらのステップを後から追加することもできます
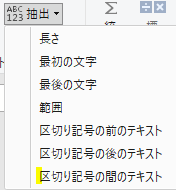
上の画像の黄色の箇所にある、変換タブ内の「データ型の検出」をクリックすると、「変更された型」のステップが追加されます
2.削除の仕方の変更
2.削除の仕方の変更では、1.とは別なアプローチでエラーを解決してみます
まず、エディタ内の画面左側から1.でエラーが発生しなくなったクエリを「複製」してみます
複製したクエリの最終ステップでは、前述のように「商品コード」以外の列を削除しています
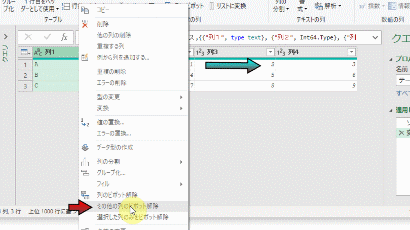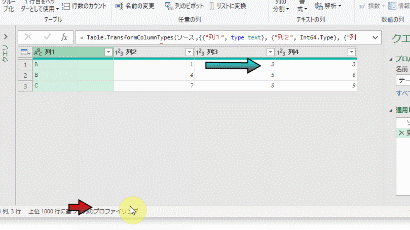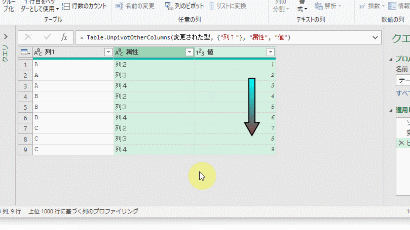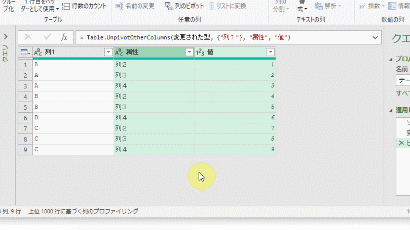
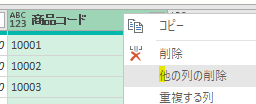
こちらのステップを削除して、次のGIF画像のように他の2つの列を1つ1つ削除します
2つの列を削除した後、エクセルシートに読込みます
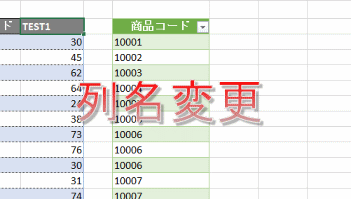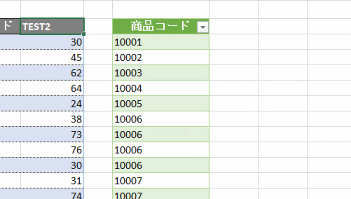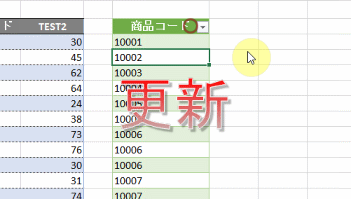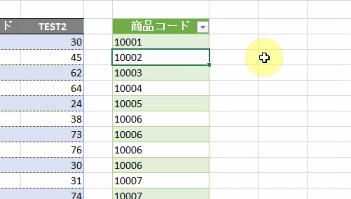
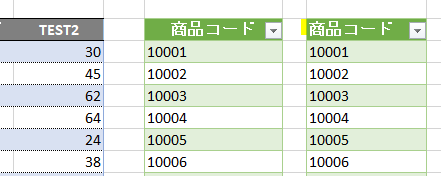
次に、列名を「TEST2」から「TEST3」に変更すると複製したクエリはエラーになります
このエラーの原因は「列の削除の仕方」にあります
下の図のように、列名変更前の「TEST2」の列名を指定して「列の削除」をおこなっているからです
こちらのエラーについては下の画像の黄色の箇所のように、列の削除の仕方を「列名」を指定しない方法(他の列の削除)で行えば発生しません
このエラーはPower Queryの「ハードコード」という特徴と深く結びついています
Power Queryでは、エディタ内の操作がステップとして記録されます
このステップ内には、値も記録されます
前述のエラーで言えば、「列名を変更する前」の列名です
こちらは、列名が変更になると「ハードコード」した列名と一致しなくなってしまい、エラーになったのです
<まとめ>
今回は、エディタ内で削除した「列名」を後から修正した場合に発生するエラーの修正方法について2つ解説しました
1つ目は「変更された型」という自動で追加されるステップを削除してエラーを回避できるようにしました
2つ目は列の削除の仕方を、削除する列名を特定しない方式に変更しました
2つの方法はそれぞれ、Power Queryの2つの特徴と深く結びついています
1つ目の「変更された型」に関するエラーは「データの構造化」というPower Queryの特徴と結びついています
エディタでデータを読み込む際に、全ての列を対象にして「見出し」「データ形式」を設定します
ですので、エディタ内で削除した列の「列名変更」がエラーの原因になります
こちらの「変更された型」については、「変更された型」のステップを削除する方法ともう一つ、対処方法があります
データタブの「データの取得」をクリックすると一番下に「クエリオプション」が出てきます
こちらをクリックすると次の画像の画面が開きます
こちらの画面で、「非構造化ソースの列と型とヘッダーを検出しない」を指定しておくという方法もあります(自動で検出されていた部分が検出されなくなるので注意が必要です)
ここまでで、Power Queryの1つ目の特徴についての「まとめ」を解説しました
次は2つ目の特徴である「ハードコード」についてです
Power Queryではエディタ内の操作が「ステップ」として記録されます
こちらの「ステップ」には値も直接書き込まれます
ですので、前述の2.で列を削除した際には「列名」も値として記録されました
ですので、エディタ内で削除した列の「列名」が変更になると、列名の「不一致」が発生してエラーになったのです
下の画像で言えば、「TEST2」の列名の列を削除するように数式が設定されていましたが、既に「TEST3」に列名が変更になっていたのです
今回はPower Queryの2つの特徴について、理解を深める機会になったと思います
この2つの特徴を理解しておくと、Power Query自体への理解も深まります
ぜひ今回を機会に「データの構造化」「ハードコード」について意識した上でPower Queryに取り組んでいきましょう!
では、今回は以上となります
参考までに今回使用したエクセルデータを添付します
長文に最後までお付き合い頂き、まことにありがとうございました


にほんブログ村