
タグ別アーカイブ: グループ化

グループ別に合計や平均に加えて標準偏差を抽出する方法
【数字は平均だけではよく分かりません。グループ化機能を更に深堀し、分析用の列に標準偏差も加えましょう!】
グループ化機能はとても便利です!グループ毎の集計を簡単に行いつつ、集計した数値を並べることができます

但し、グループ化の集計メニューには「標準偏差」が足りません
平均値を集計しても、バラツキが大きいのか、バラツキが小さいのかで平均値の解釈が違ってきます
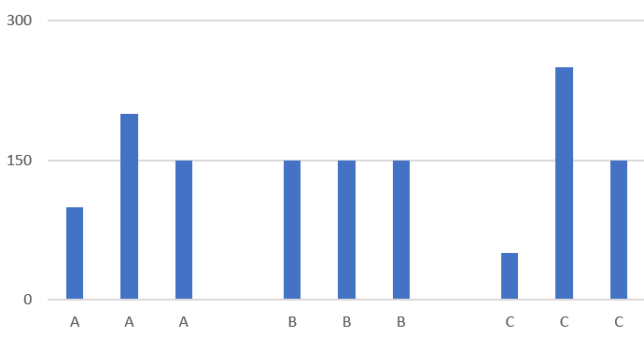
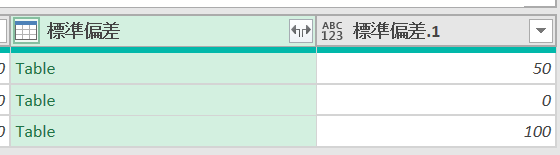
例えば、上のグラフにはA~Cという3つのグループがあります
いずれも平均は150です
ただ明らかにグループBとグループCでは平均値150の解釈が違ってきますよね
今回はグループ化のラインナップに標準偏差をサクッと加える方法を解説します
グループ化の基本
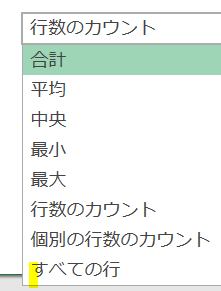
グループ化を行う際、「基本」ではなく「詳細」を選択すれば複数の集計を行うことができます

今回は「合計」「人数」「平均」を集計した後に「すべての行」を集計に加え、後で集計結果を標準偏差に集計し直します
すべての行によるグループ化
「すべての行」のグループ化により、グループ別にテーブルが作成されます
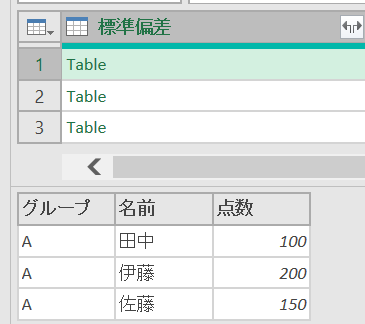
この各テーブルが配置された列を使用してカスタム列を作成します
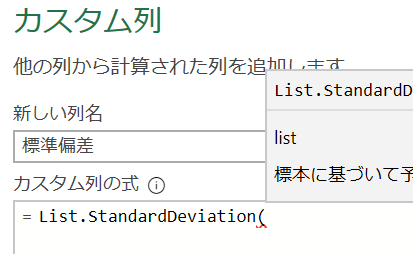
カスタム列内では「List.StandardDeviation」というM関数を使用します
使用できる列には「標準偏差」を集計する対象の「点数」の列がありません

ただ「標準偏差」の列は各テーブルの集合ですので、⇒標準偏差列⇒テーブル内の「点数」という流れで列を指定します

上の画像の「点数列」は手動で角括弧:[を使用して作成します
これでグループ別に標準偏差が集計されます
<まとめ>
今回はグループ別に標準偏差を集計する方法を解説しました
グループ化/すべての行とM関数の組み合わせにより、簡単に標準偏差を集計することができます
ワークシート関数と違い、グループ別に分けて集計する必要もなく、ピボットテーブルと違って直接テーブル化を行えるのでとても便利です
今後もPower Queryの便利術を発信していきます
![]()
![]()

DAX関数の虎の巻
こちらのコーナーでは、DAX関数*をうまく使うためのコツを解説します
*エクセルのワークシートでは関数に相当するもの
フィルター評価と行評価
フィルター評価
Power BIのレポート画面では常にフィルター評価の影響を受けます
この点は常に意識しておく必要があります
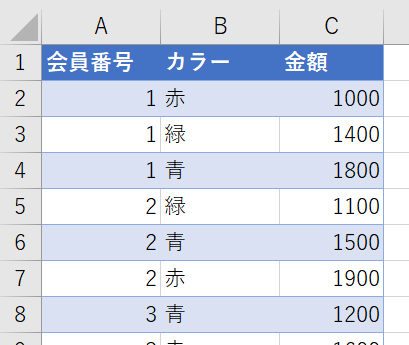
例えば、次のようなデータがあったとします
こちらのデータをマトリックスで表示すると次のようになります
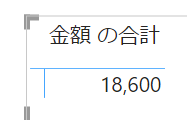
こちらのマトリックスの行にカラーを入れてみます
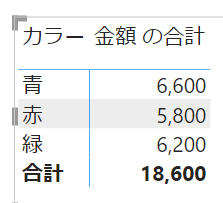
こちらは行単位で青、赤、緑のフィルターが適用されています
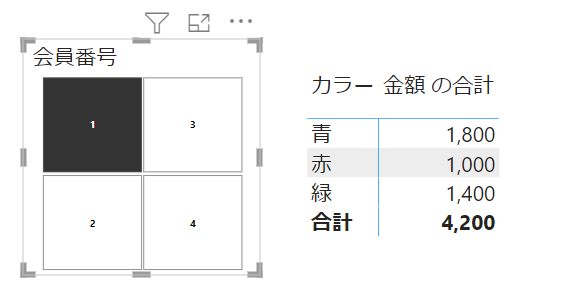
上の画像では、スライサーのフィルターが適用されています
このように、レポート画面ではフィルターの影響を常に受けるわけですが、DAXも同様です
但し、CALCULATEをDAX式で活用するとルールが変わります
試しに、青色の金額を抽出するCALCULATE関数でメジャーを書いてみます
Color_BLUE = CALCULATE(SUM(myTable[金額]),’myTable'[カラー]=”青”)

スライサーのフィルターを解除した上で、上記のメジャーをマトリックスに配置してみます
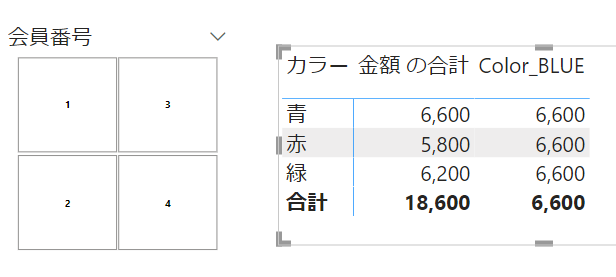
マトリックスの行単位での色別のフィルターは解除され、全て同じ値/6,600になっています
今度は、スライサーのフィルターを適用してみます
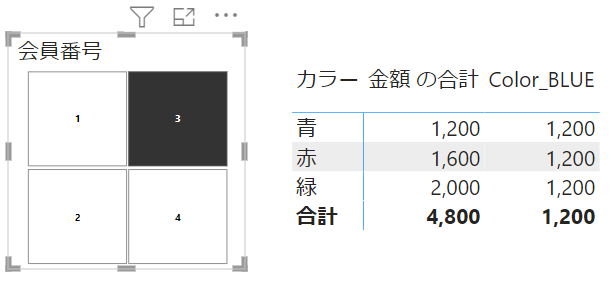
DAX外のフィルターはきちんと適用されているのが分かります
今度はメジャーにKEEPFILTERS関数を適用してみます
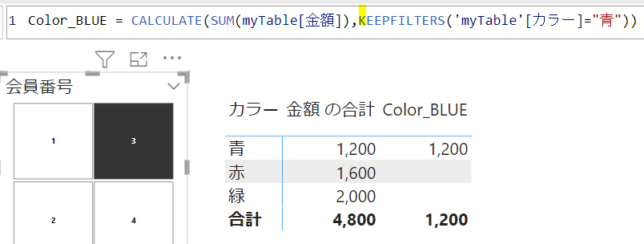
今度は、行単位での色別のフィルターが適用されています
以上、レポート画面では常にフィルターの影響を受ける点とCALCULATE関数を使うとルールが変わる点は常に意識しておきましょう!
行評価
フィルター評価と同じくらい重要で、フィルター評価より難解なのが行評価です
こちらは、明確にフィルター評価と区別して理解しましょう
例えば、次のようなデータがあるとします
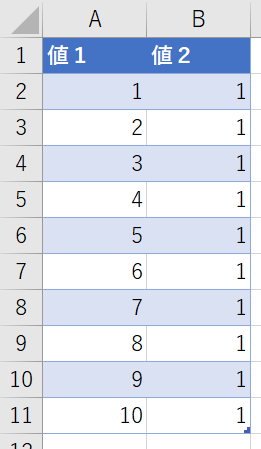
こちらのデータから、行毎に値1と値2を乗算する列を作成してみます
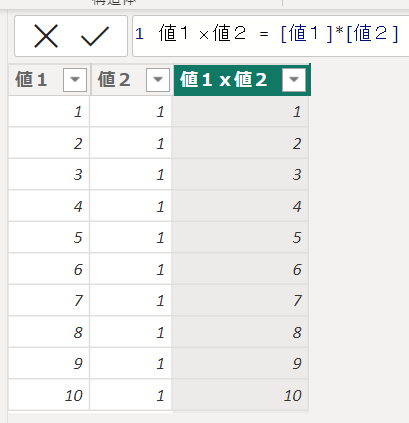
次に値1x値2の列を合計する列を作成します
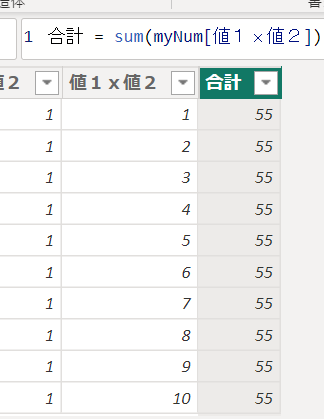
では上の画像と同じ「55」を算出するメジャーを、新しく作成した列をつかわないまま作成するにはどうしたらいいでしょう?
次のように式を書くと、突拍子もない数字になります

これはSUM関数が列自体を計算対象にしているからです
では、ここでSUMX関数を使用してみましょう!
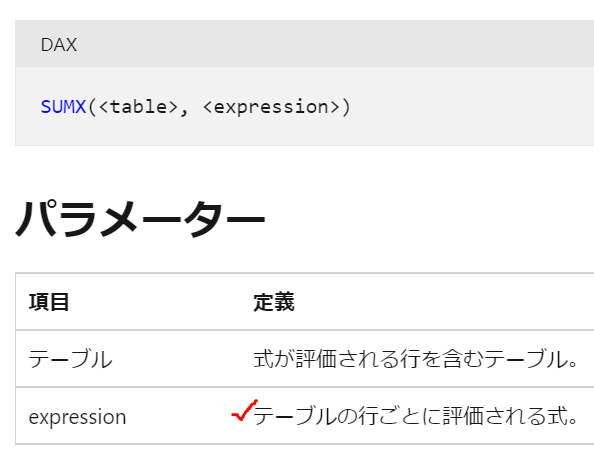
expressionの箇所が「行評価」になっています

SUMX関数を使うと、テーブル「myNum」の1行1行を計算して合計するので正しい数字が出ています
これが行評価となります
行評価では、新しい列の作成と同じように1行1行を対象とするので、フィルター評価とは明確に区別する必要があります
ちなみにCALCULATE関数を使用すると、フィルター評価と同じようにルールが変わります
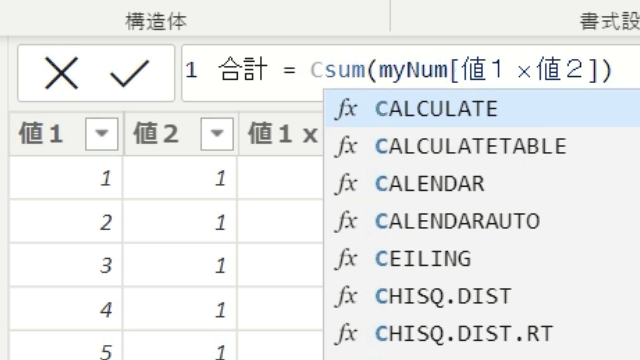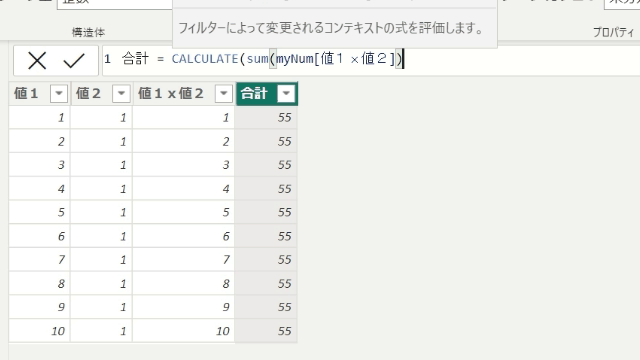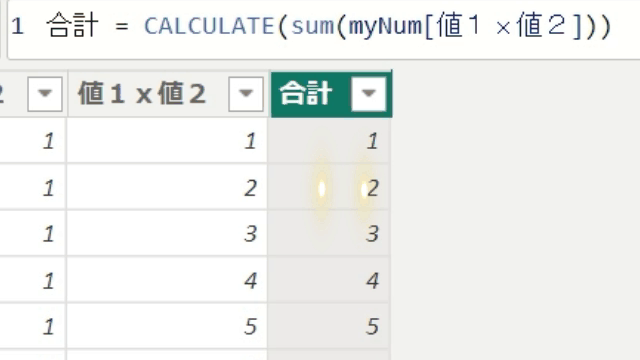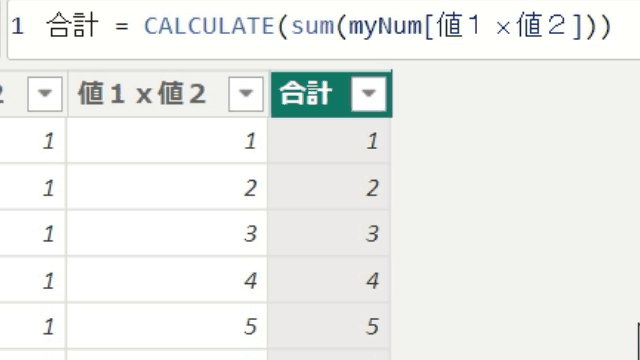
今回は、隣の列全体を合計するのではなく、1行1行の合計値を算出しています
このCALCULATE関数を使うとルールが変わる点は常に頭に入れておきましょう!
VARとRETURN~中学数学の要領でDAX使用~
DAXはVARとRETURNを使うと更に有効の活用できます
というより、VARとRETURNを使わないとかなりDAXを使う意義が薄れます
VARは変数/VARIABLEの略です
このVARを箱として活用します
エクセルのワークシートでも同じことができます
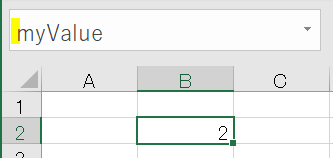
B2セルにmyValueという名前をつけました
この名前がVARに相当します
そしてD2セルで下の画像のようにmyValueを使ってみます
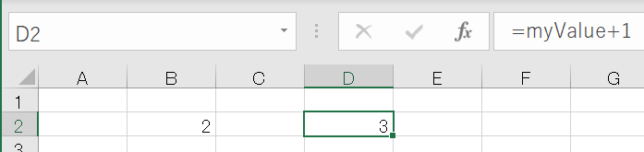
このD2セルの3がRETURNになります
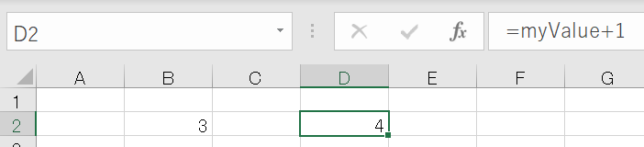
ちなみに、B2セルの値のmyValueを2から3に変えるとD4セルのリターンは4になります
では、上記と同じ内容をPower BI内でも行ってみます
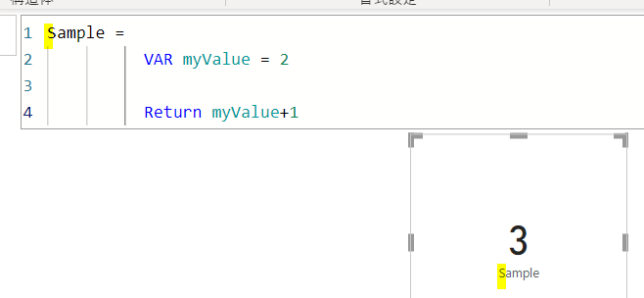
上の画像では、myValueという箱に2を入れ、更に1を加えてリターンしています
では、myValueを3にすると4がリターンします
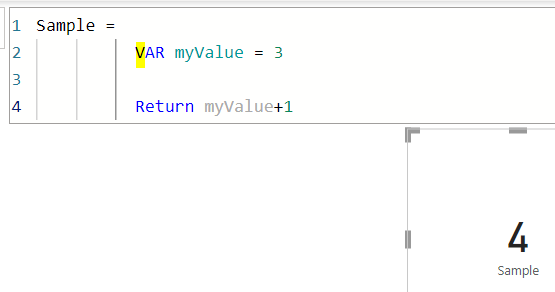
実際には、このVARを多数組み合わせて使う形になります
ALLとALLSELECTEDとの使い分け~構成比の罠~
ALLとALLSELECTEDの違いがDAXを使用したばかりだとよくわからないと思います
そもそも、ALLって何のためにあるの?という方も中にはいらっしゃると思います
ALLはスライサーなどでフィルター処理が行われた場合のためにあります

上のGIF画像では、分子がフィルターされた場合にも、分母の全体売上はALL関数により変わらないようになっています
ところが、分母の内容自体がフィルターされる場合が厄介です
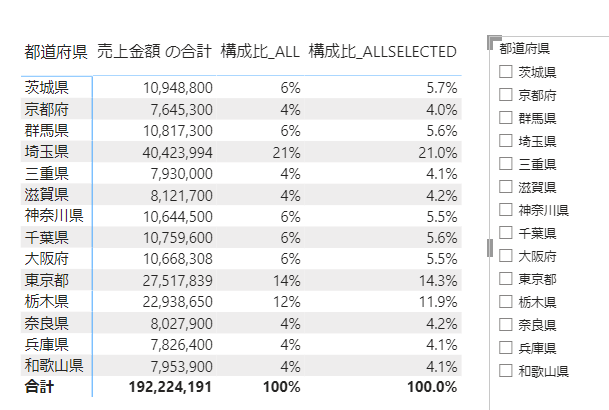
上の画像では、構成比の分母は各都道府県の合計になります
仮に3つの都道府県にフィルターした場合には次のようになります
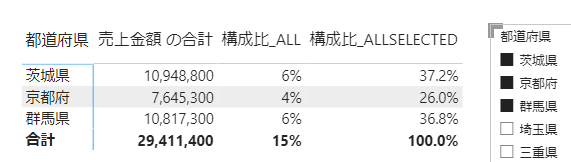
構成比_ALLの場合には、分母が固定ですから、小計が100%を割ります
構成比_ALL = DIVIDE(SUM(‘売上データ3′[売上金額]),CALCULATE(SUM(‘売上データ3′[売上金額]),ALL(‘売上データ3’)))
構成比_ALLSELECTEDの場合には、フィルターと連動して分母が動きます
構成比_ALLSELECTED = DIVIDE(SUM(‘売上データ3′[売上金額]),CALCULATE(SUM(‘売上データ3′[売上金額]),ALLSELECTED(‘売上データ3’)))
つまり、分母が何か?スライサーでフィルターする内容は何か?によってALLとALLSELECTEDを使い分ける必要があります
SUMX関数による高度な集計
エクセルのワークシート関数でもSUM系の関数は多数あります
SUM、SUMIF、SUMIFS、SUMPRODUCT・・・
DAXのSUMX関数は、ワークシート関数のSUMIFS関数とSUMPRODUCT関数を組み合わせた高性能なDAX関数です
次の表を見てください
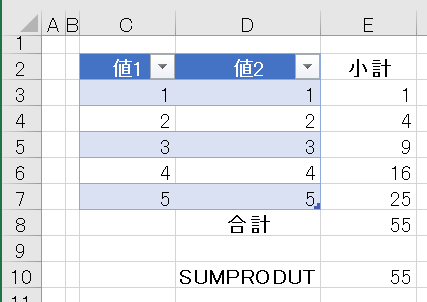
値1の列と値2の列をそれぞれ掛け合わせ、E8セルで合計しています
E10セルにはSUMPRODUCT関数が入っており、列1と列2をそれぞれ乗じつつ、各行の結果を合計しています
H3セルにはSUMIFS関数が入っており、G3セルの条件に応じて、列1と列2を乗じた値の合計を計算しています
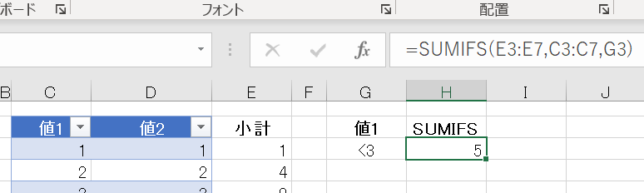
但し、Eの列で算出した値を参照しています
SUMPRODUCT関数のように、単独では計算できません
DAXのSUMX関数では、このSUMPRODUCT関数とSUMIFS関数の組み合わせを一発で計算できます
SUMX関数の文法は次のようになります
SUMX(テーブル,式)
試しに、前述のSUMPRODUCT関数と同じことをしてみます
元データは前と同じデータ(テーブル名:myTable)になります
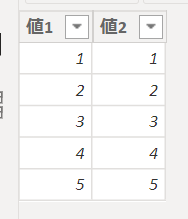
下の画像では、myTableを第一引数のテーブルとして指定し、第二引数で式を指定しています
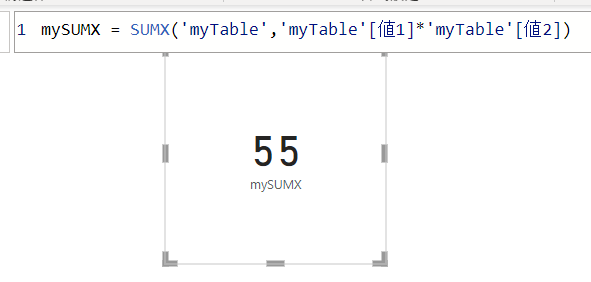
mySUMX = SUMX(‘myTable’,’myTable'[値1]*’myTable'[値2])
今度は、SUMIFS関数と同じように列1の値が<3とします
この場合は、第一引数のテーブルにFILTER関数を使います
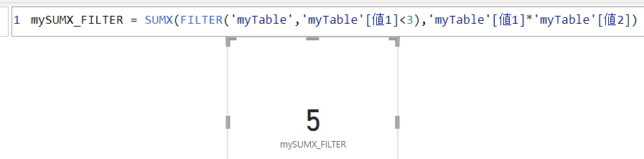
mySUMX_FILTER = SUMX(FILTER(‘myTable’,’myTable'[値1]<3),’myTable'[値1]*’myTable'[値2])
これで、SUMIFS関数とSUMPRODUCT関数との組み合わせを計算できています
嬉しいのはSUMX関数ではSUMPRODUCT関数と違い、式を自由に指定できる点です
DAXの可能性をまさに感じさせる関数だと思います
SUMMRIZE関数による一時テーブルの作成
DAX関数内で参照用の一時テーブルを作成するのにとても便利です
文法は次の通りとなります
SUMMRIZE(テーブル,集計する切り口にする列,新列名1,集計式1,新列名2,集計式2・・・)
早速、使用例を見てみましょう
元のデータは次の通りです
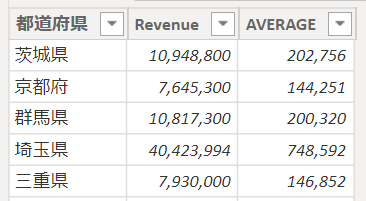
これが上の画像のテーブルから都道府県別の売上合計、平均を算出するSUMMRIZE関数の事例1です
mySummarize = SUMMARIZE(‘売上データ3’,’売上データ3′[都道府県],”Revenue”,SUM(‘売上データ3′[売上金額]),”AVERAGE”,AVERAGE(‘売上データ3′[売上金額]))
事例2として集計の切り口を都道府県のみから、商品も加えてみましょう
mySummarize+Product = SUMMARIZE(‘売上データ3’,’売上データ3′[都道府県],’売上データ3′[商品],”Revenue”,SUM(‘売上データ3′[売上金額]),”AVERAGE”,AVERAGE(‘売上データ3′[売上金額]))
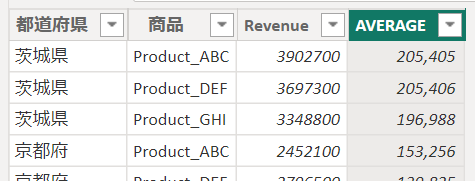
ピボットテーブルと同じような形ですよね
HASONEVALUE~値が複数か否か~
こちらのDAXは、値が複数あるケースとそうでないケースで表示を分けるのに便利です
値が複数ある場合は、FALSE、そうでない場合はTRUEを返します
ただ、上記の説明だと使用シーンが明確に浮かばないとおもうので実際の例を見てみましょう

上の画像にあるようなメジャーを作り、カレンダーテーブルの内容を行に仕込んだマトリックスの中にいれてみます
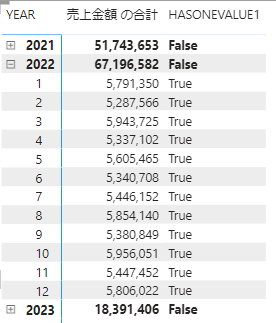
すると、MONTHの箇所は一つしか値がないのでTRUEになり、YEARの箇所はMONTHが複数あるのでFALSEになります
次にもう一つメジャーを作成します

IF式を使い、HASONEVALUEがTRUEであれば、金額を表示するようにします
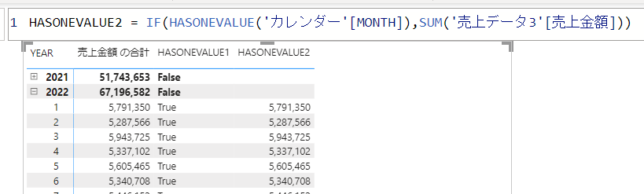
YEARとMONTHで表示を切り替えられるようになりました
ISBLANKとISEMPTY~空白?空欄~
ISBLANKとISEMPTY、似てるようで明確に違いがあります
具体的には何が違うのでしょう?
ISBLANKは対象が列、ISEMPTYはテーブルが対象になります
ISBLANK
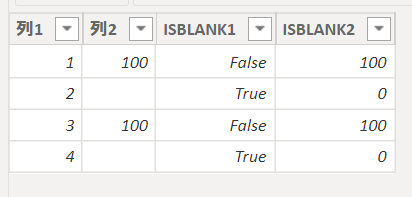
下の画像では「ISBLANK1」という新しい列を追加しています
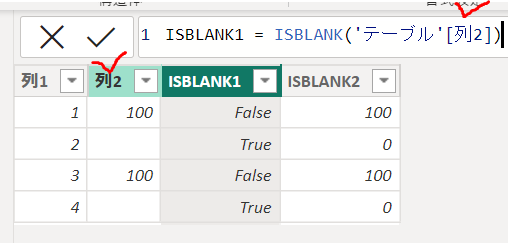
空欄の行では「TRUE」を返しています
次の画像ではIF式と組み合わせて空欄を0に置き換えています
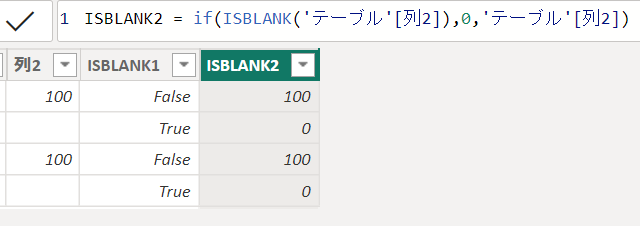
ISEMPTY
ISEMPTY関数を使い、次のようなメジャーを作成してみます
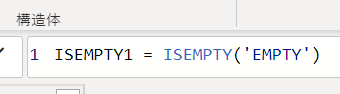
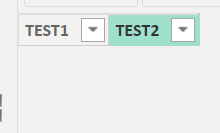
上の画像内の「’EMPTY’」は次の画像のテーブルです
このメジャーの内容をカードで出力してみます
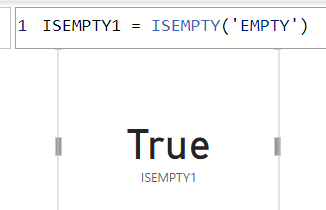
こちらはTrueで出力されます
今度はISEMPTYの中身のテーブルを変えてみます

’テーブル’は空でないのでFalseが返されます
REMOVEFILTERS関数~フィルターの影響を避ける~
思わぬところでフィルターの落とし穴にはまったことはないですか?
以下のグラフでは折れ線グラフが100%のまま水平になっています
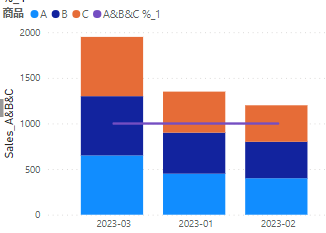
これは元のデータにはABCだけでなく、EやFもあるのです
ただ、フィルターがかかっています
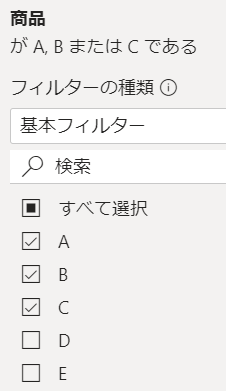
このフィルターがかかっている状態にて、折れ線グラフで使用するメジャーは次のような数式になっているのです

分子のメジャーは商品ABCの合計です
分母は全体の合計です
ただ前述のようにフィルターはABCにかかっています
ですので分母は常に商品ABCです
だから100%のままです
この場合にREMOVEFILTERS関数を使用します

A&B&C %_2 = DIVIDE(‘DATA'[Sales_A&B&C],CALCULATE(SUM(DATA[値]),REMOVEFILTERS(‘DATA'[商品])))
このREMOVEFILTERS関数により、商品に対してかかっているフィルターを取り除きます
そうすることで分母を常に正しく計算することができます
ちなみにALL関数を使うと時系列でのフィルターがかからないため、分母が異常に大きくなってしまいます
SUMMARIZECOLUMNS関数~簡単にグループ化~
SUMMARIZECOLUMNS関数を使用すると、下のようなデータを簡単にグループ化することができます
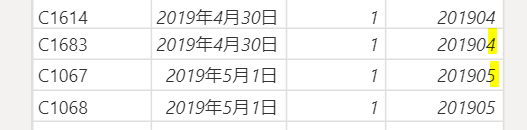
新しいテーブルからこのDAX関数を使用してみます

yyyyMM列をグループ化の切り口として「月小計」という列を作成し、「月小計」に受注数のグループ別の小計を計算します

NewTable=SUMMARIZECOLUMNS(①’OrderData'[yyyyMM],②”月小計”,③SUM(‘OrderData'[受注数]))
たった3つの引数だけで作成できるのでとても便利です
①:グループ化の切り口、②新列名、③計算式
こちらの関数は次のように変数にSUMMARIZECOLUNS関数で作成したテーブルを代入して使用することもできます
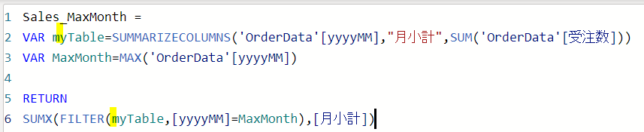
Sales_MaxMonth = VAR myTable=SUMMARIZECOLUMNS(‘OrderData'[yyyyMM],”月小計”,SUM(‘OrderData'[受注数]))
VAR MaxMonth=MAX(‘OrderData'[yyyyMM])
RETURNSUMX(FILTER(myTable,[yyyyMM]=MaxMonth),[月小計])
CALCULATE関数にて複数条件を指定する
CALCULATE関数は条件を指定しながら様々な集計ができる便利なDAX関数です
複数条件を指定する場合には次のような式になります
AND条件
CALCULATE関数に条件を追加する場合には「コンマ」を追加します
例えば、下の画像のデータから(商品=A)and (月=202303)という条件で合計金額を集計したいとします
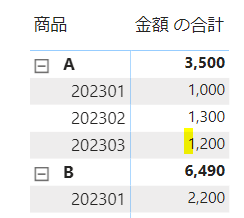
その場合のメジャーは次のようになります
商品:A and 月:202303 = CALCULATE(SUM(‘DAX1′[金額]),’DAX1′[商品]=”A”,’DAX1′[月]=202303)
OR条件
OR条件の場合には「||」を使用します
商品:A or 商品:B = CALCULATE(SUM(‘DAX1′[金額]),’DAX1′[商品]=”A” || ‘DAX1′[商品]=”B”)
この場合、「in」を使用するという方法も使えます
商品:A or 商品:B_in使用 = CALCULATE(SUM(‘DAX1′[金額]),’DAX1′[商品] in {“A”,”B”})
SWITCH関数とTRUEの組み合わせ
通常
SWITCH関数は場合分けをするケースでとても便利です

注文金額3 = SWITCH(‘分析用2′[注文金額],1200,”1200″,8600,”8600″,”X”)
IF関数と比べて条件を複数追加することができます
ただ条件設定が「=しか指定できない」、「指定順序が間違いやすい」などの問題があります
TRUE
SWITCH関数の第一引数を「TRUE」とすると、もっと柔軟に条件を指定できるようになります
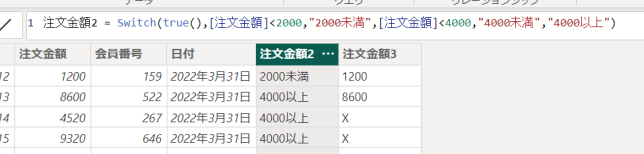
注文金額2 = Switch(true(),[注文金額]<2000,”2000未満”,[注文金額]<4000,”4000未満”,”4000以上”)
RANKX関数~順位付け~
DAXのRANKX関数を使えば、集計した値に対して順位付けが行えますのでとても便利です
RANKX関数の文法自体はとても簡単なものですが、実際には少々トリッキーな面があります
文法:RANKX(使用テーブル,順位を判断する値)
*実際には他にも指定できます
作成してみたけど結果が全て1になってしまった、という方も中にはいらっしゃると思いますので、トリッキーな面を中心に解説を行います
解説に使用するテーブル/テーブル名:Tableは以下です。カテゴリーが大小2つあります
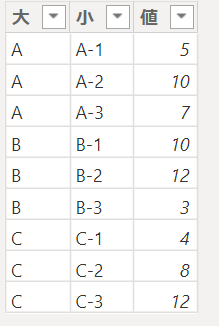
こちらのデータから大、小のカテゴリーにて順位付けを行えるようにします
判断に使用する値は予めメジャーで算出しておきます
これが1つ目の大きなポイントです

次に実際にカテゴリー大を順位付けするメジャーを作成します

ここでAllを使用するのが2つ目の大きなポイントです
そして、Allの引数はカテゴリー列も指定します
Allを使用しないと、ビジュアルで表示する時にフィルターが効いて全て1になります
他の言葉で言い換えると、フィルターが効いても他の行の値と比較して順位付けできるようにします
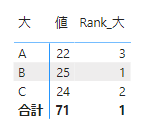
では次にカテゴリー小を順位付けするメジャーを作成します

このメジャーをマトリックス表にセットしてみます
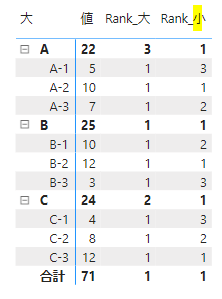
こちらは大カテゴリー内での順位が出力されます
今度は、カテゴリー大の関連はマトリックス表から抜いてみます
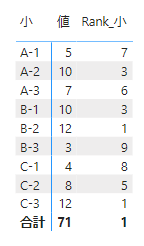
これでカテゴリー小の間で順位付けが行えました
繰り返しになりますが、順位付けを行う値は事前にメジャーにしておきましょう!
DISTINCTCOUNTROWS vs DISTINCT vs VALUES
一見、同じに見えるこれらの関数ですが、何が違うのでしょうか?
試しに、これらの3つのDAX関数を使用して下の画像のテーブルにて「客先名」をカウントするメジャーを作成してみたいと思います
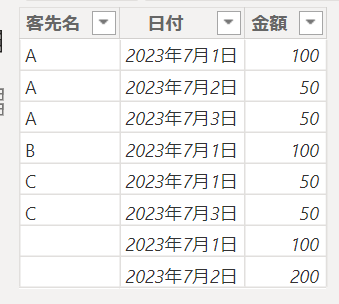
実際に作成するメジャーの中身は次の通りとなります
ちなみにDISTINCT関数とVALUES関数はCOUNTROWS関数と組み合わせます
CountBY DistinctCount = DISTINCTCOUNT(‘売上テーブル'[客先名])
CountBY Distinct = COUNTROWS(DISTINCT(‘売上テーブル'[客先名]))
CountBY Values = COUNTROWS(VALUES(‘売上テーブル'[客先名]))
結果は全く同じ結果になります(空欄もカウントしています)

ではどのような時に結果が違ってくるのでしょうか?
今度は客先マスタで客先名をカウントしてみます
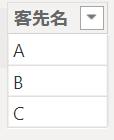
但し、先ほどの売上テーブルとリレーションを組んでおきます
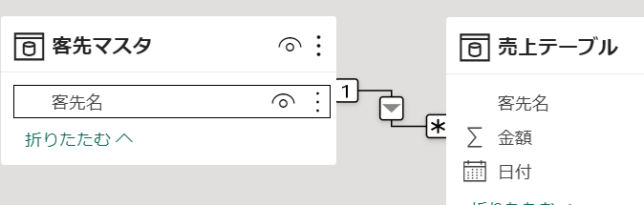
実際に作成するメジャーは次の通りとなります
CountBY DistinctCount = DISTINCTCOUNT(‘客先マスタ'[客先名])
CountBY Distinct = COUNTROWS(DISTINCT(‘客先マスタ'[客先名]))
CountBY Values = COUNTROWS(VALUES(‘客先マスタ'[客先名]))
結果は次の通りとなります

VALUES関数だけ売上テーブルの空欄をカウントしているという結果になりました
CalculateTable関数~テーブルの作成~
テーブルを作成する際に便利なのが、CalculateTable関数です
CalculateTable関数は条件付で計算をするのに便利なCalculate関数のテーブル版です
文法も一緒で、出力されるのがテーブルというだけです
テーブル関数も幾つかありますが、CalculateTable関数を使うケースは次のようなケースが典型的です
Customer IDs = CALCULATETABLE(VALUES(OrderData1[Customer ID]),OrderData1[yyyy-MM]=”2019-07″)
上のDAX式ではVALUES関数と組み合わせて、注文データ/OrderData1から2019年7月に注文があった会員の番号をリスト化しています
こんな風に1列をリスト化するVALUES関数と組み合わせて、条件に合うリストを作るケースなどで便利です
更には「VAR~RETURN」と組み合わせて、CalculateTable関数で出力したリストから更に別なものを出力するといった事もできます
EOMONTH関数~時系列で日付を整理する~
時系列で日付を整理するのに便利なのが、EOMONTH関数です
例えば前月末日を知りたいとします
その場合は次のようにメジャーを書きます

これだけで自動的に前月末日が出力されます
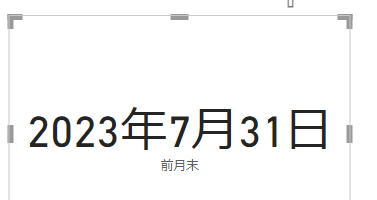
では、前月開始日を出したい場合にはどうしたらいいでしょうか?
その場合は「+1」をうまく使います

これで、開始日も自由に抽出できます

フィルターが複数あるケースで割合を計算する~Calculate&AllSelected&removeFilters~
よくこんな風にフィルターがスライサーを含めて複数かかるケースがあります
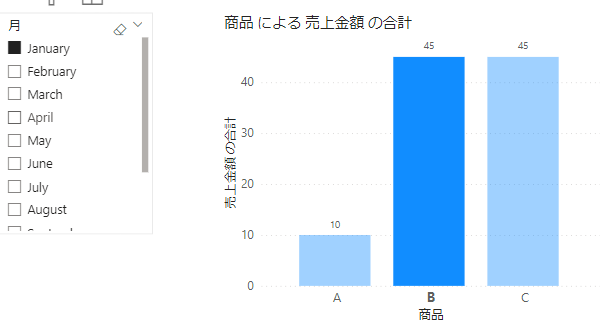
上の画像のケースでは「日付、しかも月」「商品」の2つです
この場合、グラフ内の選択商品の割合をどうやって計算しますか?
下の画像の場合は商品A~Cの合計が100で、選択された商品Bは45なので45%です
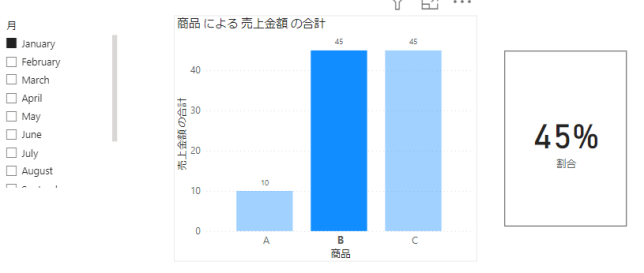
分子は該当の「月」で該当の「商品」の売上金額です
つまり純粋に選択されたものです
ですので以下のメジャーで簡単に算出されます
CALCULATE(SUM(‘テーブル'[売上金額]),ALLSELECTED(‘テーブル’))
では、分母はどうでしょう?意外と難しく感じられませんでしょうか?
フィルターは「月」だけです
ですが、Calculate関数内で指定できるのは「日付単位」です
この場合は、Calculate関数内で次のようにRemoveFilters関数を組み合わせればあっさりと解決します
CALCULATE(sum(‘テーブル'[売上金額]),ALLSELECTED(‘テーブル’),REMOVEFILTERS(‘テーブル'[商品]))
こちらが割合を計算するメジャーです
割合 =
VAR bunshi=CALCULATE(SUM(‘テーブル'[売上金額]),ALLSELECTED(‘テーブル’))
VAR bunbo=CALCULATE(
sum(‘テーブル'[売上金額]),
ALLSELECTED(‘テーブル’),
REMOVEFILTERS(‘テーブル'[商品])
)
RETURN DIVIDE(bunshi,bunbo)
![]()
![]()
複数グループ内で値違いの箇所を見つける~グループ化の応用~
先日ある方から大量の商品データの中から、価格違いの設定が起こっているところを見つけたいという依頼がありました
またルールがあり、同じ素材/同グループであれば販売する色種類が違っていても同じ価格で設定しなければいけないということでした
もちろん、目でみて判断することもできますが、大量データがある場合にはとても困難です
こういった場合はPower Queryのグループ化機能で簡単に価格違いが起こっているグループを見つけることができます
今回は次のデータを使って解説を行いたいと思います
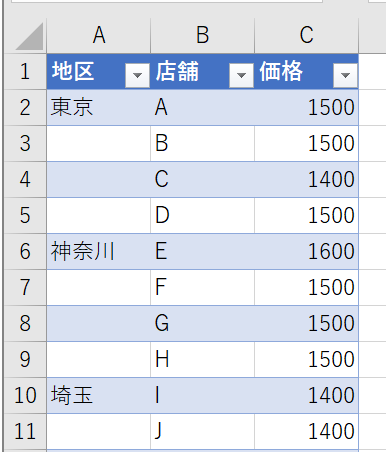
ある商品を価格設定するときに、地区内では同じ価格設定にしなければならないものとします
こちらのデータから価格違いが起こっている地区を見つけます
ポイント
Power Queryのグループ化機能では、グループ化の方法として「最小」「最大」がありますので、こちらを活用します

グループ化の適用
解説はPower Queryエディターからはじめさせて頂きます
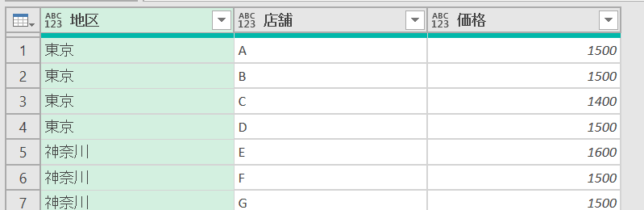
ちなみに、上の画像では元のエクセルデータにフィルを適用していますので空欄が埋まっています
上記の画像の状態からまずグループ化をクリックします
デフォルトでは「基本」設定になっていますが、今回は「詳細設定」を指定します
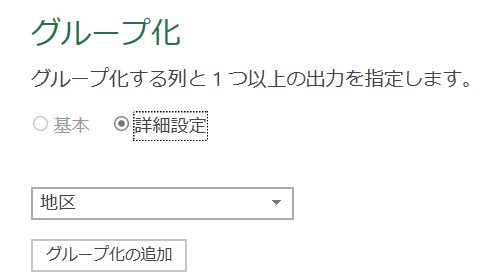
こうすることで、「集計の追加」ボタンにより、グループ化の集計方法を「最小」に加えて「最大」も指定することができます

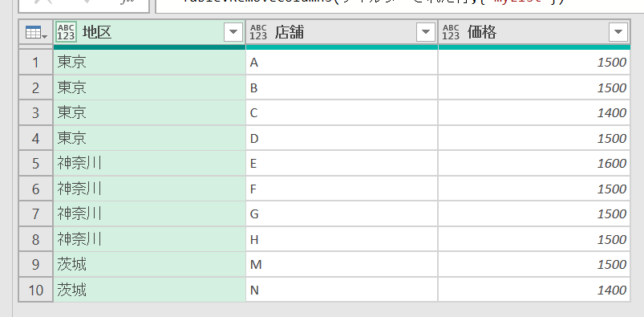
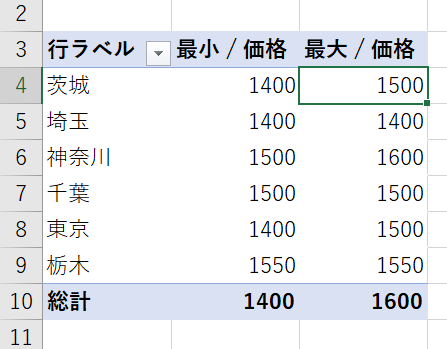
グループ化を実際に適用すると下の画像のような状態になります
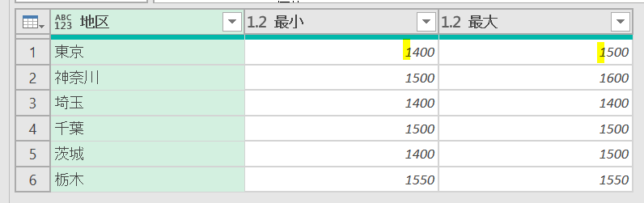
グループ内にもし価格違いがあると、上の画像の黄色の箇所のように「最小:1400<>最大:1500」となります
条件列の作成
ここからは条件列を作成して、最小と最大が違うときは「X」そうでなければ「〇」という表示をする列を作成します
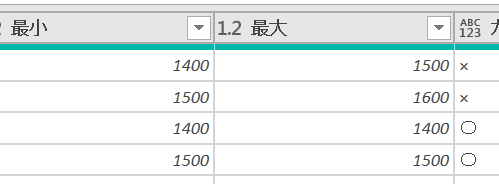
条件列は次のように設定します

価格違いがあるグループと明細リストの抽出
上の条件列を作成すると下の画像のような状態になっています
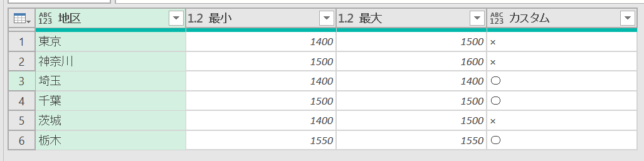
もちろん、「×」の箇所だけフィルターをすれば、グループ内で価格違いが起こっている箇所は分かります

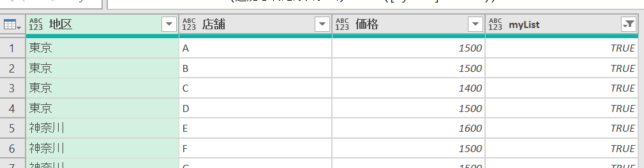
ただ、下の画像のように店舗と価格もリストにしたいとします
目で元のデータをフィルターする方法もありますが、M関数を使い、自動的にフィルターする方法もあります
まずは下の画像の状態で、適用したステップを「myList」とするところから解説を始めたいと思います
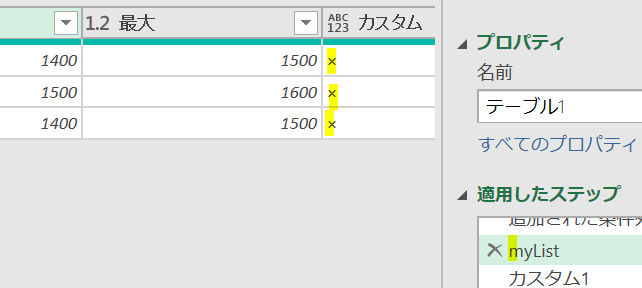
後でこちらの「myList」を参照します
次に
関数マーク/fx*をクリックしたステップを追加した後に、元の「フィルした状態/下方向へコピー済みステップ」を参照します
*参照ステップの記事を参照
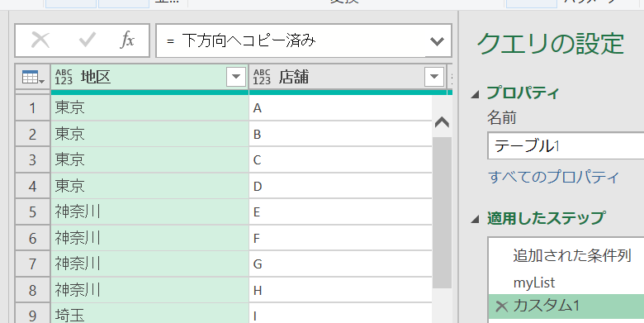
これで、グループ化を行う前の状態に戻りました
ここから「地区」列がmyListに含まれるかどうかを判定する列を「カスタム列」作成画面で作成します
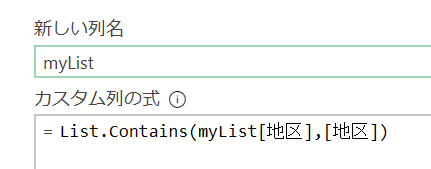
List.Contains関数を使うことで、地区の列の値が「myList」ステップの地区列に含まれるかどうかを判定できます
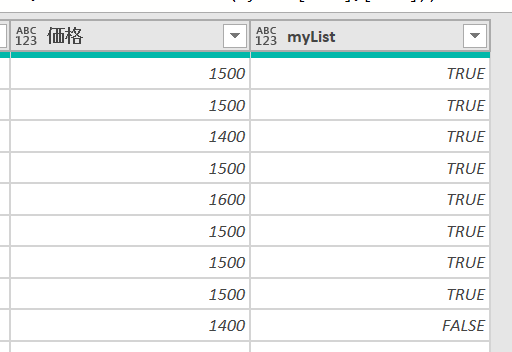
ここから「TRUE」のみをフィルターすればリストは完成です
<まとめ>
今回は、グループ化機能の最小と最大をうまく組み合わせて、グループ内の違う価格設定を発見する方法を紹介しました
ピボットテーブルでも同じことができます
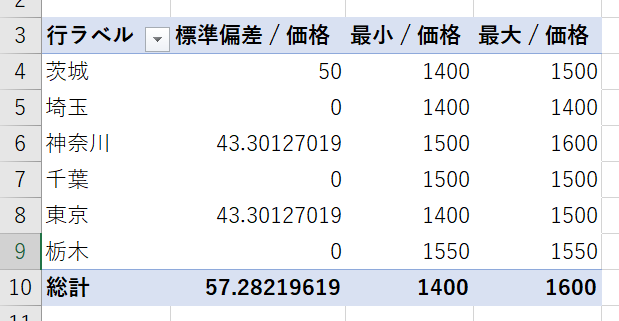
ピボットテーブルの場合には分散や標準偏差を出す方法もあります
グループ内で価格にバラツキがある場合には、分散や標準偏差が0以外になります
![]()
![]()
分布図の作成及びグループ化~データを見やすく分解する
ピボットテーブルのグループ化機能を使うと、数字が見やすくなるため重宝しておりますが、Power BIでも同じようなことが行えます
今回は、Power BIにおけるグループ化機能を量/ヒストグラムと質に分けて解説します
分布の把握は数字分析の基本なので、分析を行う必要のある方には特に有用な情報だと思います
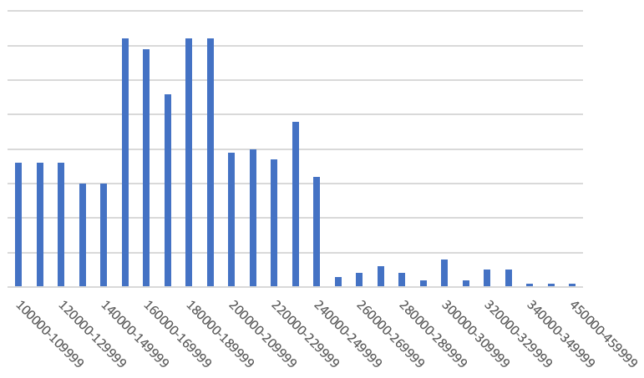
量によるグループ化
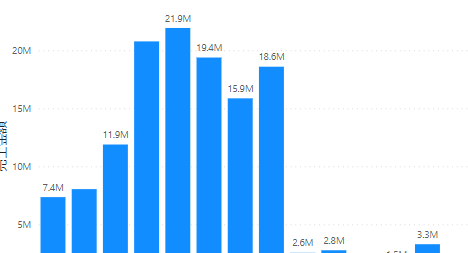
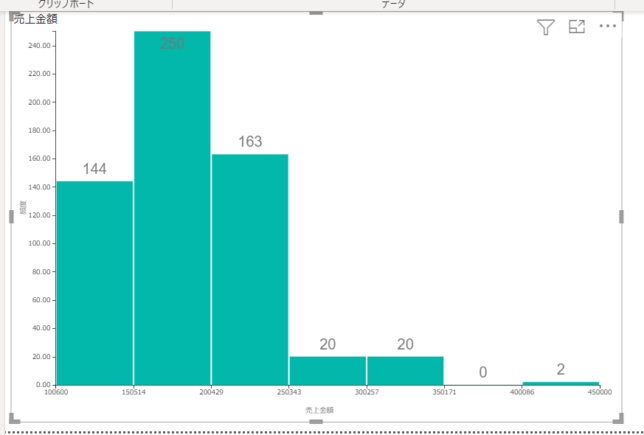
今回は下の画像のデータからヒストグラムを作成したいと思います
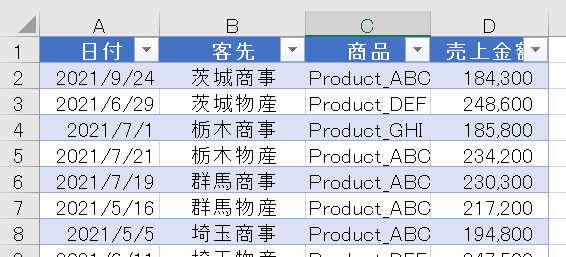
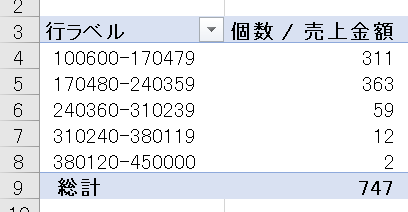
売上金額の範囲区分を一定の金額で設定し、レコード数(行数)747件の件数を範囲区分別に縦棒グラフで表示します
まず、レポート画面のフィールド欄で「売上金額」上で右クリックします
すると「新しいグループ」という表示が見えますので、こちらをクリックします
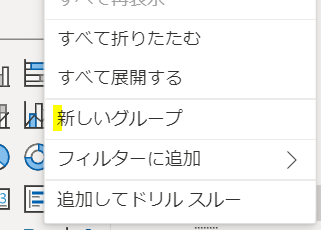
「新しいグループ」をクリックした後は、次の画像の画面が開きます
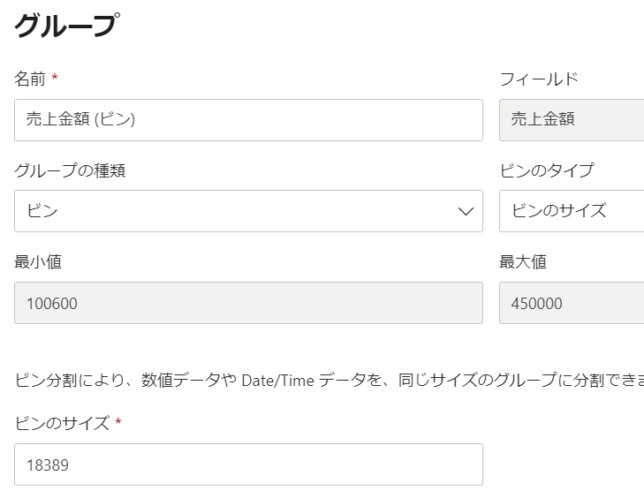
ピンのタイプはデフォルトで「ピンのサイズ」になっていますが、こちらは「ピンの数」に変更します
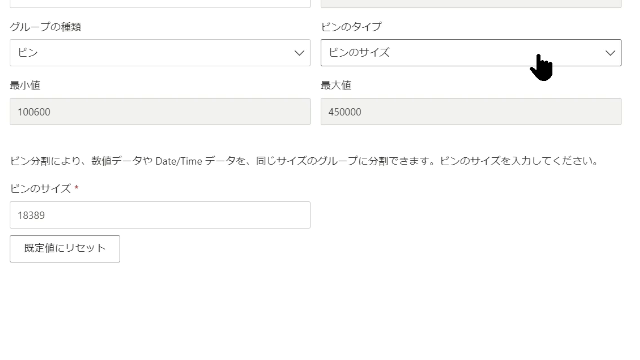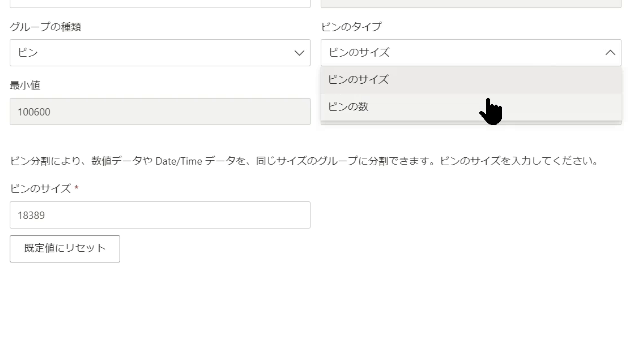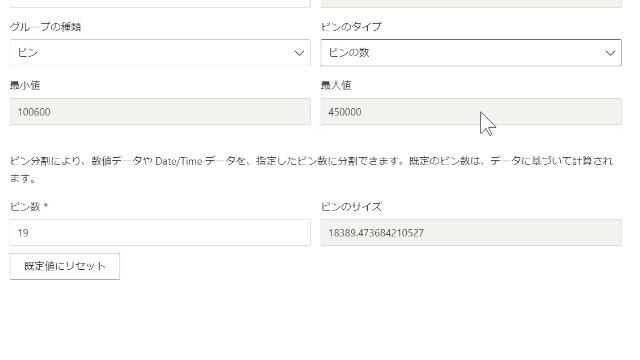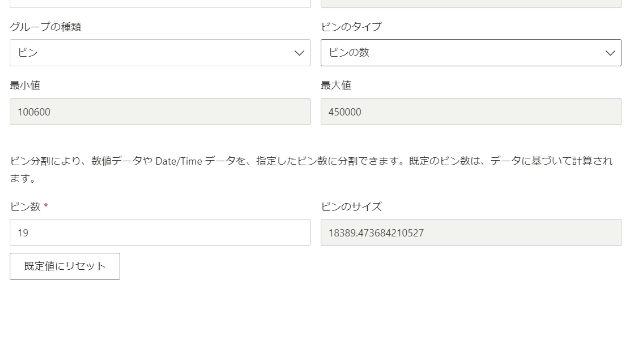
ここで「ピンの数」とは縦棒の数になります
OKボタンを押すと、新たなフィールドができます

こちらをX軸に配置し、Y軸に売上金額のカウントを配置します

すると、縦棒グラフがヒストグラムとなります
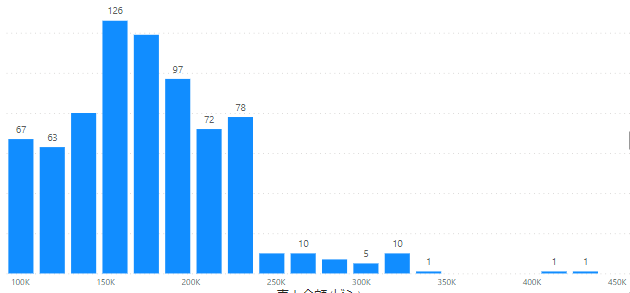
ヒストグラムのデータ区分の範囲はピンのサイズとなります
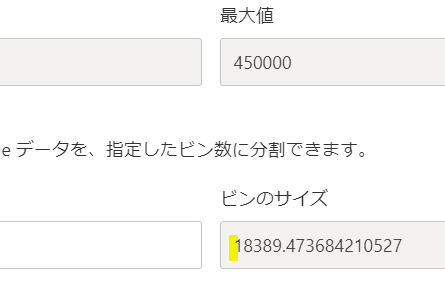
ちなみにY軸を合計に変えるとデータ範囲別に合計金額を表示することができます

質によるグループ化
こちらのグループ化はレポート管理画面の一つ下のデータ管理画面で行います

下の画像がグループ化を行うデータです
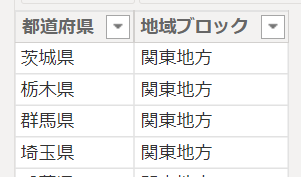
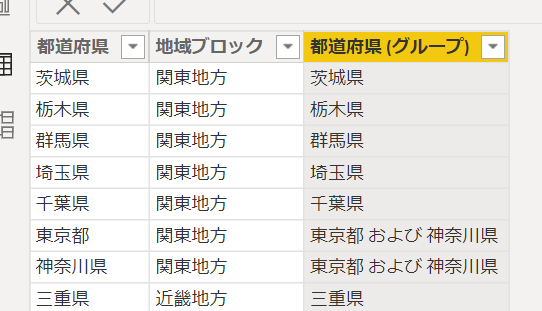
まず、グループ化の対象になる「都道府県」の列を選択します
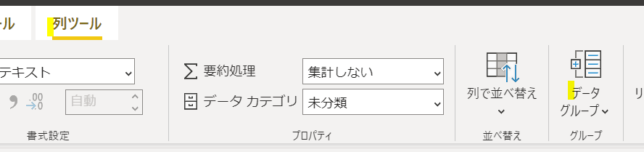
すると上のタブが「列ツール」に切り替わり、「データグループ」が表示されます
ここで「データグループ」の▼マークをクリックすると次の画面が表示されます
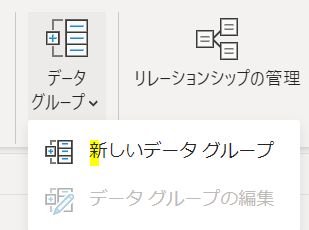
「新しいデータグループ」をクリックすると表示が次のように切り替わります
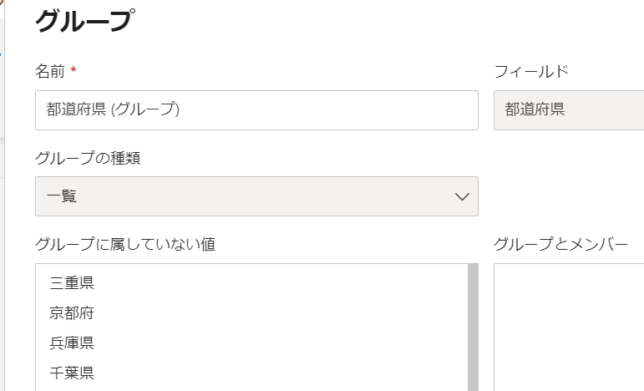
ここでグループ化するものは、Ctrlキーを押しながら選択し、グループ化をクリックします
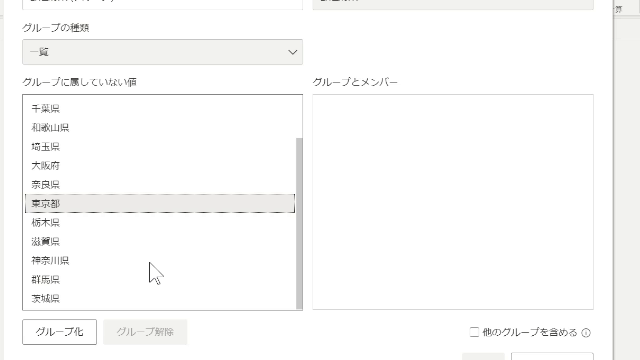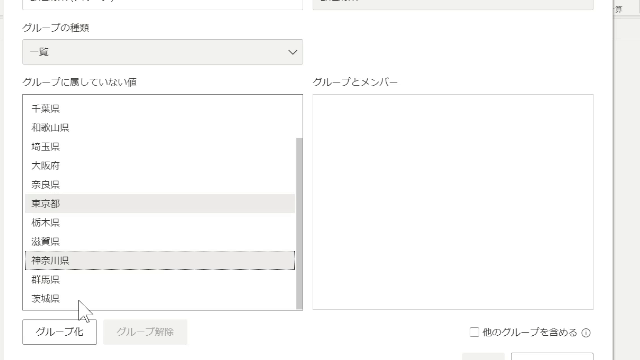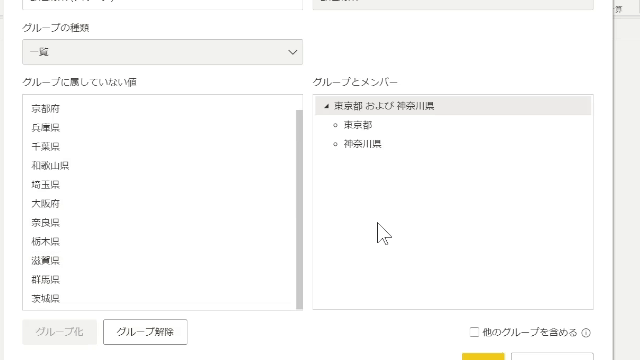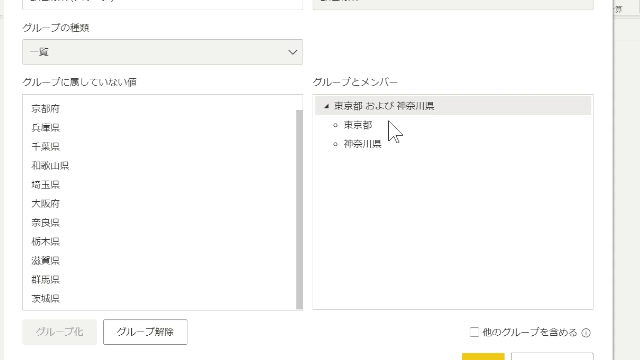
この選択、グループ化の処理によりグループ化が実施されます
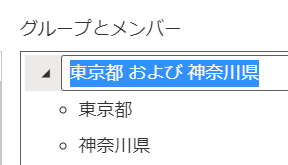
仮に、この状態のまま画面右下のOKボタンを次のような列ができます
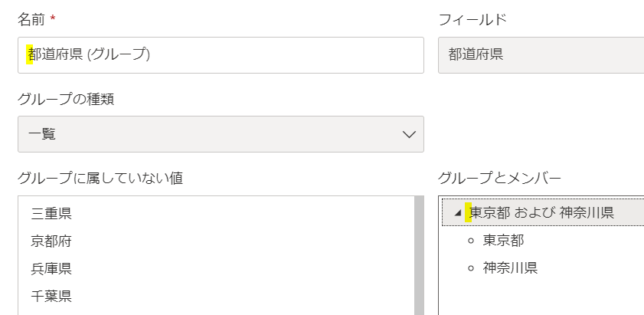
ですので、列名およびグループ名はOKボタンを押す前に修正しておきます
<まとめ>
今回は量と質の双方の観点からグループ化を行う方法を解説しました
Power BIではグループ化により、分析可視化だけでなく、分析作業も行えます
ヒストグラムについては、X軸の範囲が良く見えない点について不便に感じる方もいらっしゃると思います
その場合には、「その他のビジュアルの取得」から「histogramのアプリ」を探す方法もあります
ヒストグラム/histogramは複数種類がありますので、ぜひ試してみてください

上の画像の「Histogram Chart」ならばX軸も下の画像のように明確に表示されます
![]()
![]()
【M言語実践】顧客の2回目のリピート率を分析する方法
パワークエリはとても便利ですが、M言語となると使い道がよく分からないと思います
今回は、M言語を使用した実践的な分析手法を紹介したいと思います
私は以前、EC通販会社に勤めていました
EC通販では顧客の顔が見えないので、データからどういう顧客がいて・どういう行動をしているのか・を分析する必要があります
様々な分析を行いましたが、指標として一番重視していたのが「顧客の2回目リピート率」です
顧客の2回目のリピート率が何故重要なのか?
これには様々な理由がありますが、一番の理由は2回目のリピート率を少しでも改善すれば、売上が長期的に増加するからです
読者の方でも外食をした際に「あの店には2度と行かない・・・」という経験をした方も多いと思います
逆に同じ店で2度食事をして、その店に慣れてくると3回目、4回目とリピートする意欲する気が高くなると思います
ビジネスでも「2回目のリピート」というハードルをクリアすることの意義はとても大きいのです
ただし、普通にエクセルで2回目のリピート率を算出しようとするとかなり面倒です
私は一時期、IF関数で注文回数を付与して、2回目の注文だけシートを分けたりしていました
ましてや、2回目のリピートの有無別に顧客分析をしようとするとかなりハードルが高いです
ところが、M言語を使えば2回目のリピート率は意外と簡単に算出できます!
ポイント
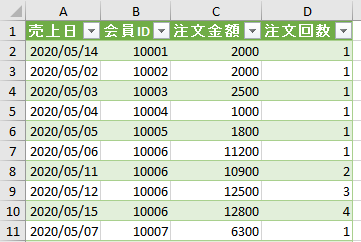
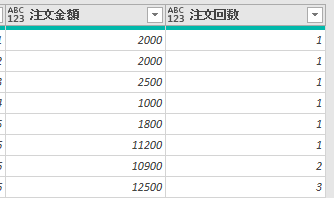
今回使用するデータは会員別の注文データです

上の画像では2回目の注文があった会員に黄色の印を付けましたが、2回目の注文があった会員もいれば、そうでない会員もいます
ここからまず、会員番号毎に注文回数を付与します
そして、上の画像の表から次のような表を作成します
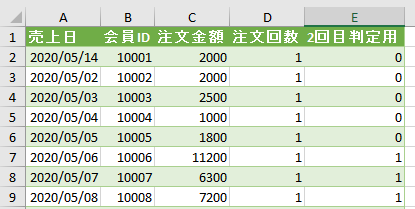
上の画像では、その前の画像の表から注文回数を「1回」に絞り込んであります
結果として、会員番号の列は会員番号が重複なく並んでいます
そして「2回目判定用」なる列が追加されています
こちらは注文回数の差分です
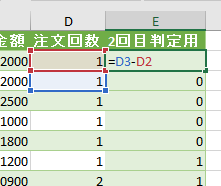
こちらの差分は注文回数を「1回」に絞り込んだ場合には0か1になります
この列が1の会員は2回目の注文があった会員です
つまり、「2回目判定用」の列の合計を「注文回数」の列の合計で割れば2回目のリピート率が出るという仕掛けになります
(注)尚、上記の画像のデータ以前に注文履歴は無いという前提で解説を行わせて頂きます。ですので、本当は初回の注文ではないのでは?という疑問は持つ必要はありません
注文回数の付与
ポイントで解説した通り、まずは会員番号別に注文回数を付与します
こちらについての詳細については、過去の記事をご確認をお願いします
大きく分けて2つ行うことがあります
1つ目は、グループ化です
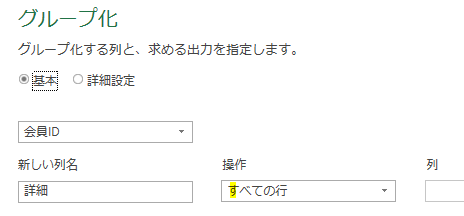
会員ID別(会員番号別)に「すべての行」でグループ化を行い、会員ID別にテーブルを作成します
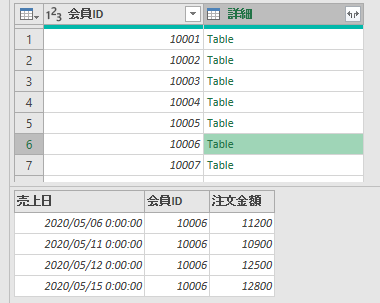
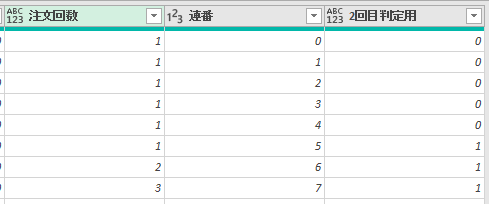
次にカスタム列・作成画面にて、テーブル別にM関数/Table.AddIndexColumnを使用して連番を付与します
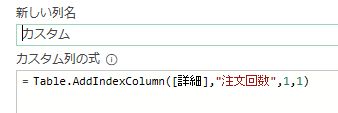
すると、注文回数が連番で付与されます
注文回数の差分の算出
こちらについても詳細は過去の記事をご参照願います
この差分を算出するには、パワークエリでは本来は困難な「セル単位」や「行単位」の処理に踏み込む必要があります
ポイントとなるのは、こちらも「連番」です

上の画像のように連番をつけると、連番と画面左の行番号とが対応するようになります
ちなみに、M言語は0ベースなので、実際にM言語で使用する1行目は0になります
ここから波括弧:{}を使用します
波括弧は行番号を表します
例えば、注文回数{0}とした場合には、注文回数列の1行目のデータなります
この波括弧と連番をうまく組み合わせることで、注文回数の差分を算出します
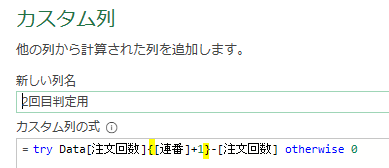
上の画像にて黄色の印を付けた波括弧内は、注文回数の各行の1つ下の行番号の値になります([注文回数]の前のDataは前ステップの名称になります)
つまり上の画像内では、注文回数列をA列だとすると<=A3-A2>と同様の計算が行われています
ちなみに、try~otherwiseとすることでエラーを回避しています
注文回数の絞り込み
上記まで行ったところで、エディタを確認すると以下の画像のような状態になっています
ここから注文回数の列にフィルターをかけます
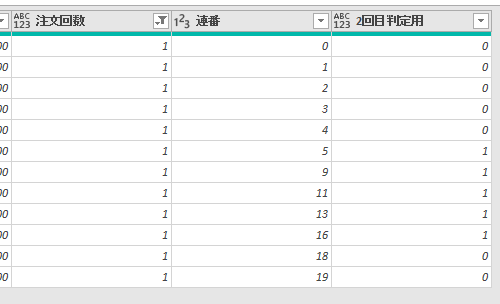
こうすれば注文回数の列は「1」のみ、2回目判定用の列は0か1になります
ここまでくれば、後は各列を合計して2回目のリピート率を算出するだけです
合計にはM関数/List.Sum関数を使用します

上の画像では、2つの合計値を/で割り算をすることでリピート率を算出しています
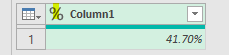
%の表示にしたい場合には、List.Sum関数でリスト化した内容をテーブル化した上で%に型式を変えます
<まとめ>
今回はM言語の仕組みを使用して、2回目のリピート率を算出しました
2回目のリピート率を算出するのに、主に2つのM言語の技術を活用しました
1つ目はグループ化を通じて各グループ毎に連番を付与する仕組みです
2つ目は注文回数の差分を連番と波括弧を組み合わせて算出する仕組みです
この2つの技術を通じて、注文回数と2回目の注文有無を0か1で表現できるようにしました
今回は2回目のリピート率を算出しましたが、本当に大事なのは2回目のリピートがあった会員とそうでない会員との違いは何かを調べることです
今回作成したクエリを複製して途中のステップを削除すれば、会員番号別に注文の有無が表示できます
他のデータを会員別に紐づければ、2回目の注文があった会員とそうでない会員の購入している商品の違いなども調べることができるはずです
更に注文回数の差分を抽出する仕組みを応用して、初回から2回目までの日数なども調べることができます
M言語が本当に有効なのはこういった複雑な分析が必要な場面だと思います
特にグループ化から連番を付与する仕組みと差分を算出する仕組みは、分析作業にて使う場面も多いと思いますので、しっかり活用できるようにしておきましょう!

マスタデータの履歴管理を行う方法
パワークエリの「クエリのマージ機能」はとても便利で、エクセル関数のVLOOKUP関数より使いやすいです
「クエリのマージ機能」を有効活用すれば、参照表(マスタデータ)の活用もかなり手軽に行えます
今回の記事では、「クエリのマージ機能」に加えて「グループ化機能」も活用して、マスタデータを更に有効に活用できるようにする方法を解説します!
マスタデータの履歴管理
マスタデータには顧客マスタや商品マスタなど様々なものがあります
種類は様々でも、絶対的なルールが一つあります
これは、マスタデータには重複があってはならないということです
もし、マスタデータのIDが「1,2,3・・・」と採番されていたとしたら、IDの1が2つあってはならないということです
ところが、
マスタデータの変更履歴を残す必要がある場合があります
例えば、以下の画像のケースです
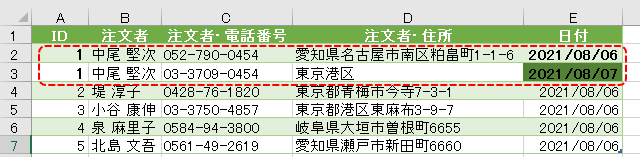
上の画像は顧客マスタです
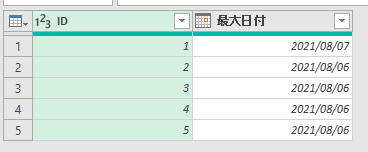
ID:1番の中尾さんのマスタデータが重複しています
何故かというと、IDが1番の中尾さんが名古屋市から東京に引っ越ししているからです
ただし、データ管理上は前の住所も残しておく必要があります
この場合は、日付が最新(最大)のもののみマスタデータとして表示できるように工夫する必要があります
では次から、日付が最新(最大)のもののみをマスタデータとして表示する為のポイントを2つ紹介します
ポイント
グループ化
パワークエリにはグループ化という機能があり、重複を排除してグループ化しつつ合計処理などの操作を行えます
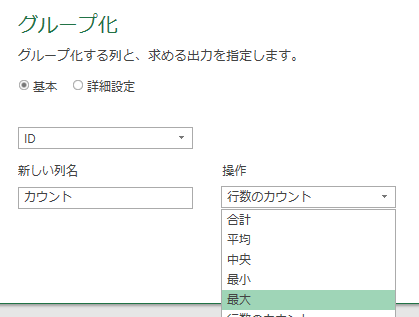
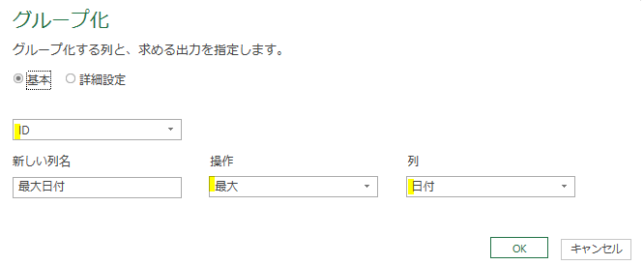
今回はグループ化機能の操作を「最大」で指定して、IDの重複がある場合には「最大の日付」のものを抽出できるようにします
複数キーによるマージ
エクセル関数のVLOOKUP関数では、検索値は一つのみ指定できます
パワークエリのマージ機能では、実は、複数列を照合列として指定できます
手順
マスタデータからクエリ作成
解説は、前述のマスタデータをテーブル化してエディタを開くところからははじめさせて頂きます
エディタを開いたら、下の画像の日付の列が時刻表示になってしまっています
こちらは、日付形式に直しておいてください
日付形式に直したら、クエリ名を「顧客マスタ_元」としてください
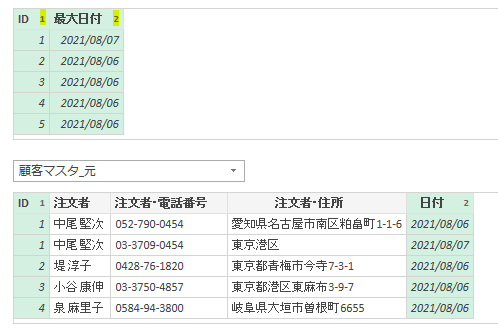
グループ化による最大日付の抽出
まずは「顧客マスタ_元」クエリを「複製」してクエリ名を「顧客マスタ_グループ化」に変更してください
この後、ポイントで前述したように下の画像のような設定でグループ化を行ってください
グループ化を行うと、前述のID:1番の方の日付が最新の日付になっているはずです
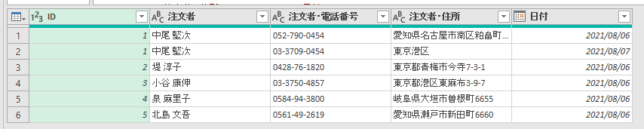
クエリのマージ処理
では、次にクエリのマージを指定しますが、下の画像の「新規としてクエリをマージ」を指定して、新規にクエリを作成できるようにします
マージ対象のクエリは下の画像のように「顧客マスタ_元」を指定します
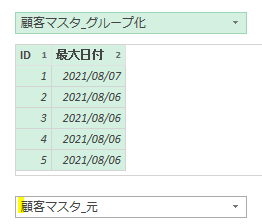
ポイントの章で前述したように、複数の列を照合列として指定します
今回のケースの場合は、IDだけでなく「日付」も指定することで、IDに重複がある場合には、日付も一致したマスタデータのみをマージできるようにします
下の画像のように照合列として複数列を指定する場合には、Ctrlキーを押しながら指定します
マージする条件を指定した後は、マージされたクエリの中かから「ID列と日付」以外を展開します
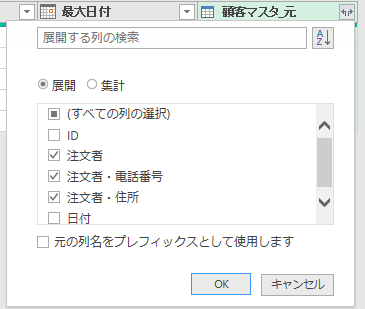
マージされた列を展開した後は、列の順番等を整えてください

<まとめ>
今回は、パワークエリのグループ化機能とマージ機能をうまく組み合わせてマスタデータの履歴管理を行う方法を解説しました
今回の最大のポイントはグループ化機能です
グループ化を行う際に、操作を「最大」にして日付が最大のもののみを抽出できるようにします
今回解説した内容で一点、注意点があります
マージする際に、グループ化した内容は1番目にくるようにしてください
元の顧客マスタは、上の画像にて黄色の印をつけた箇所のように、2番目に来るようにしてください
この順番が狂うと、IDが重複したままになってしまいますので注意が必要です
【分析】RFM分析の「F」を集計する
RFM分析は顧客を3つの指標で分類して、顧客別に施策を講じる手法です
Recency いつ?、Frequency 頻度?、Monetary いくら?
今回は、上のFrequencyを顧客別に集計する方法を解説させて頂きます
このFrequencyとは、データ内に出現する「顧客ID別の出現回数」のことです
まず何故、このFrequency/頻度を分析するかという話しをしたいと思います
例として同期間内の注文頻度が10回で注文総額が10万円の顧客グループと、注文頻度が1回で注文総額が10万円の顧客グループを比較して考えて見ましょう
平均注文金額は前者が1万円であり、後者は10万円となります
両グループとも、同期間内の注文総額は一緒です
ですが注文単価が違うことから、注文に含まれる商品の単価も注文の仕方も違う可能性が高いです
加えて、後者は期間限定の「値引き商品」をまとめて購入している可能性も高いです
つまり「頻度」を抽出することにより、顧客の注文行動における特性を炙り出せるのです
今回の使用データと行いたいこと
今回の解説で使用するデータは、次の画像の注文データです

注文データは、注文日が2021年1月から3月までの期間で集計されています
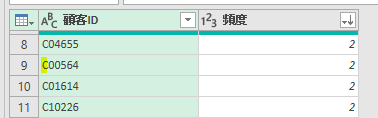
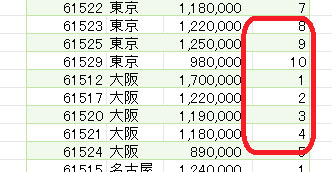
このデータから顧客ID別に、注文頻度を抽出します
例えば、上の画像にある顧客ID「C00564」の顧客ならば2回と抽出できるようにします
頻度の集計
解説は元データをPower Queryエディタで開くところからはじめます
こちらの集計処理は、過去の記事でも紹介したグループ化により一瞬で終了します
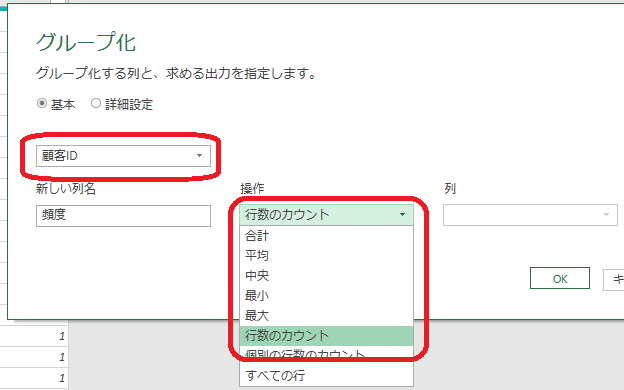
まずは「ホーム」タブの「グループ化」をクリックします
するとグループ化・画面が開くので、次の画像のように各項目を設定します

グループ化項目:顧客IDの列

新しい列名:頻度
操作:行数のカウント
この上記の設定により、顧客ID別にIDの登場頻度が集計されます
<まとめ>
今回はRecency いつ?、Frequency 頻度?、Monetary いくら?の内、Frequencyを集計しました
グループ化の機能を使えば、簡単に頻度も集計できます
グループ化機能は分析を行う上では欠かせない機能です
実際に手を動かして実践的に活用できるようになりましょう


M言語に慣れる_10回目~グループ毎に連番作成~
【M言語は難しくない】今回はデータをグループ化した際に、1から始まる連番をグループ毎に作成する方法について解説します。この処理の仕方を覚えると、エクセルの使い方の幅が広がります
コードの採番や顧客の2回目のリピート状況把握など、使いみちは沢山あります!
しかも知られざるグループ化機能を使えば、1つのM関数を入力するだけでできてしまいます
まさに魔法です
ぜひ、実際に手を動かしてこの魔法を体験してください!
目次
今回のポイント
今回のポイントは2つあります
グループ化
グループ化する際に、よく選択される操作は「合計」などです
今回は「すべての行」という操作を選択します
この「すべての行」を選択して操作を行うと、グループ毎にテーブルが作成されます
M関数作成
連番は「列の追加」タブの「インデックス列」のメニューから、クリック操作で簡単に作成できます
今回は、既存のメニューは使用せず、カスタム列の作成画面から「Table.AddIndexColumn」というM関数を使用して「連番」を作成します

M関数で作成することで、ポイントの1点目で作成されたグループ毎のテーブルを、関数の引数として指定できるようになります
今回の使用データ
今回は下の画像にあるデータの「部門」列をグループ化します
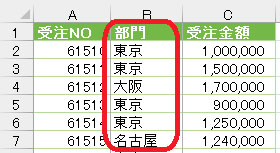
グループ化した後は、グループ毎に連番を振ります
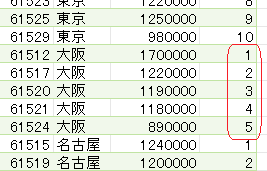
以下が実際に使用するサンプルデータです
グループ化の実施
解説は、前述のデータをテーブル化し、エディタを開いたところから行います
エディタを開いたらまずは、グループ化を行います
グループ化は「ホームタブ」の「グループ化」メニューから行います
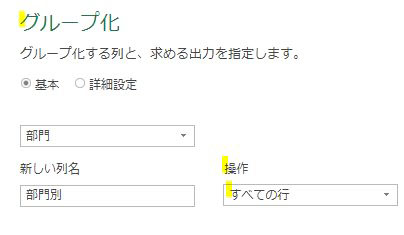
次に開いた画面では、前述のように操作を「全ての行」で設定します
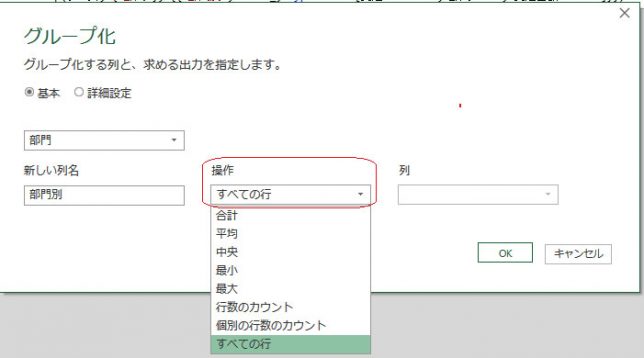
・グループ化対象列 ➡ 「部門」列
・新しい列名 ➡ 「部門列」
・操作 ➡ 「すべての行」
・列 ➡ 空欄のままでOKです
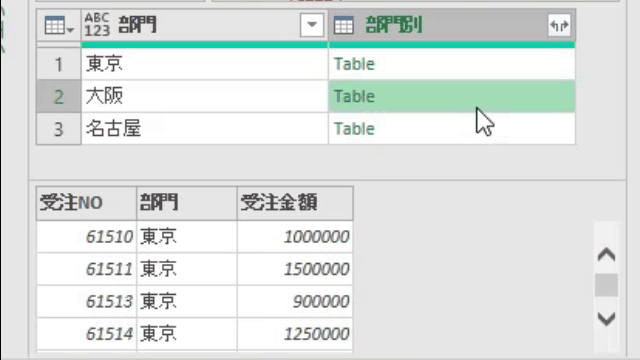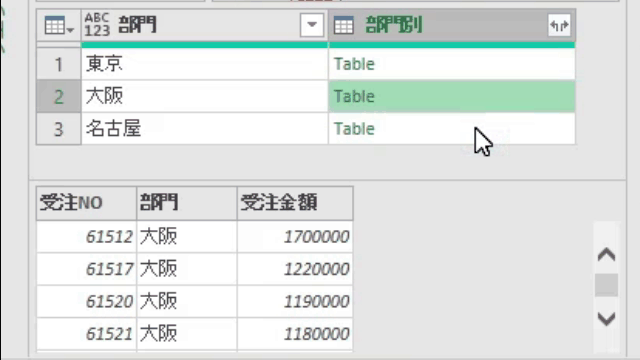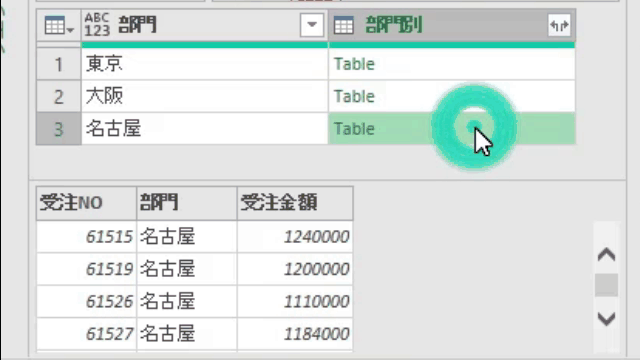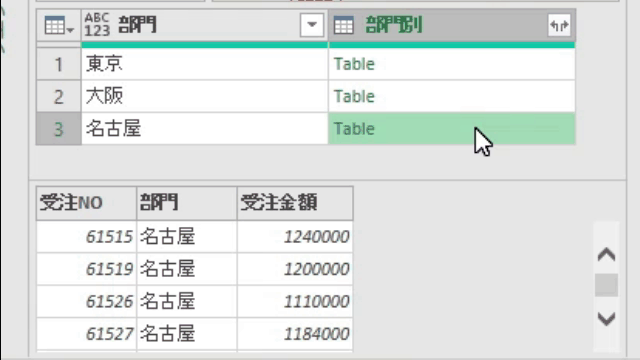
上の内容で指定してOKボタンをクリックすると、エディタ内では次の画像のように、テーブルがグループ別に作成されています
【M言語に慣れる】_14回目_複数行を1つのセルにまとめる
【M言語は難しくない】今回は複数行に拡散している値を、次のGIF画像のように「記号」をつなぎ目にして、1つのセルにまとめます
今回のポイント
今回のポイントは2つあります
1つ目は過去記事で紹介した「すべての行」によるグループ化です
この「すべての行」によるグループ化により、グループ別にテーブルを作成します
2つ目はリストの「値の抽出 / 1つのセルにリスト化」機能の活用です
こちらは、実際の例で見てみましょう!
空のクエリで次の画像のように、2つのリストを作成したとします
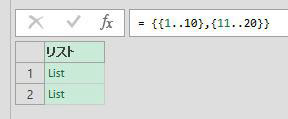
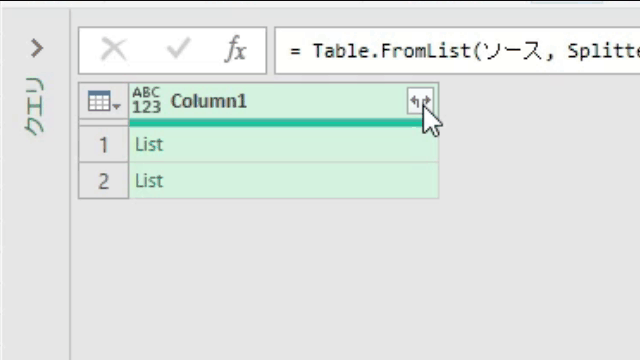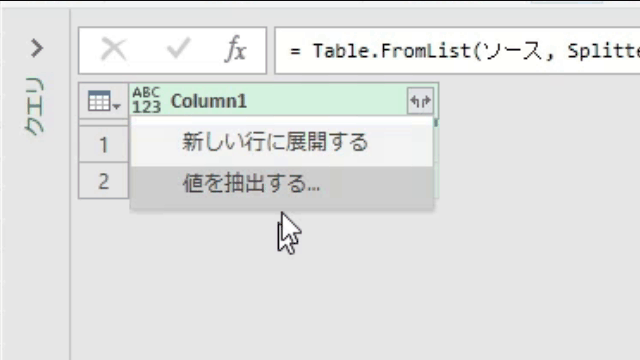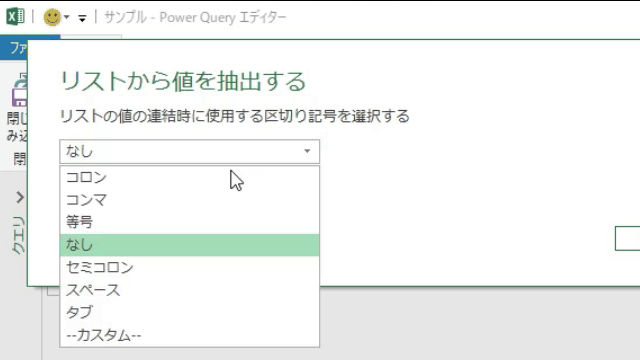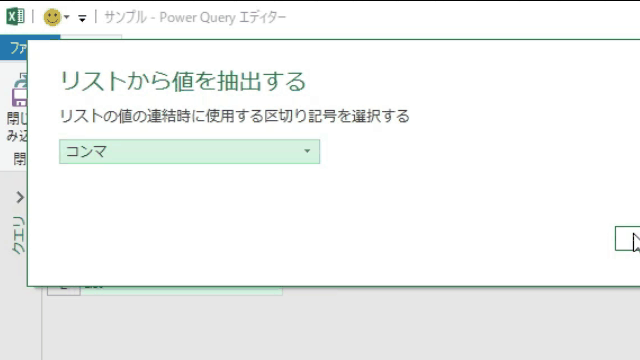
上の画像のリストを一旦、テーブル化した後、黄色に印を付けた「展開マーク」をクリックをすると「値を抽出する」が選択できます
上のGIF画像のように「値を抽出する」を選択した後は、リストの「区切り記号」を指定できます
「区切り記号」を指定した後は、下の画像のように1つのセルにリストの値が出力されます
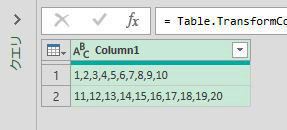
今回使用するデータ
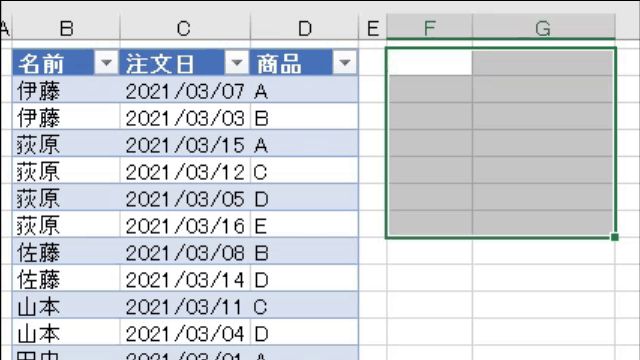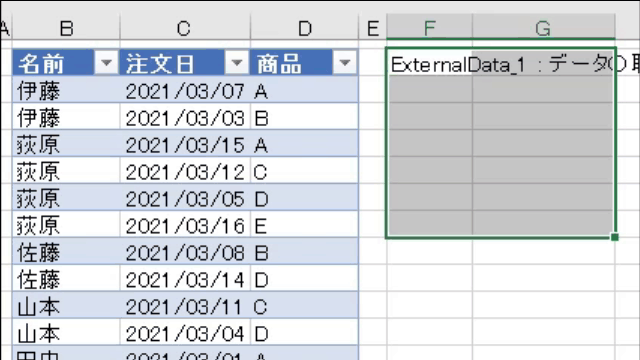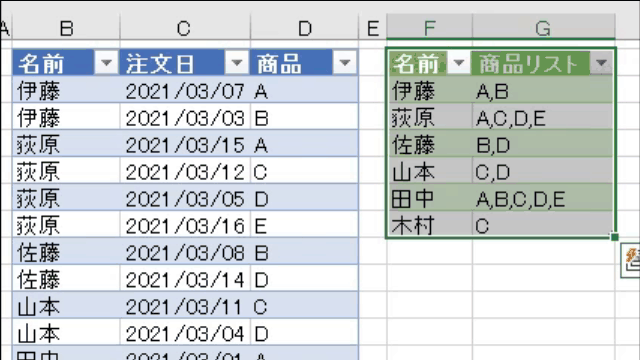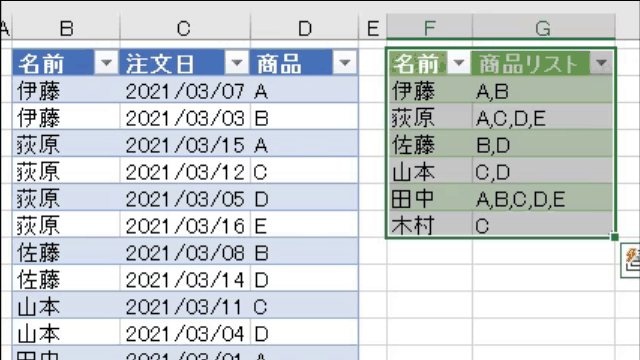
今回使用するデータは、次の画像のデータです
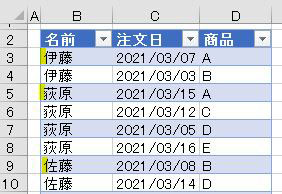
名前の列をグループ化し、グループ毎に「商品列に含まれる商品」を1つのセルに出力します
グループ化の実施
今回の解説は、使用データをエディタで開くところから始めます
上の画像にて、黄色の印を付けた「グループ化」をクリックします
なお、事前に「注文日」の列は削除しておきます
グループ化の内容は次の画像のように指定します
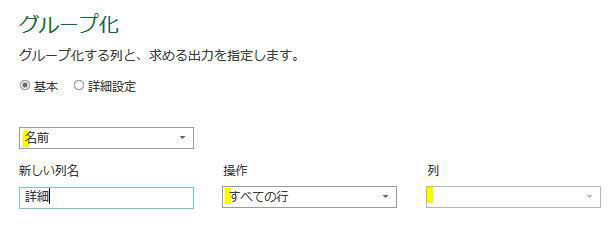
・グループ化項目:名前の列をグループ化します
・新しい列名:詳細
・操作:前述のように「すべての行」を指定します
・列:空欄のままでOKです
上記のように指定してOKボタンを押すと、エディタ画面は次のようになります
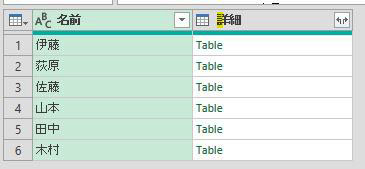
グループ化された名前毎に、テーブルが作成されています
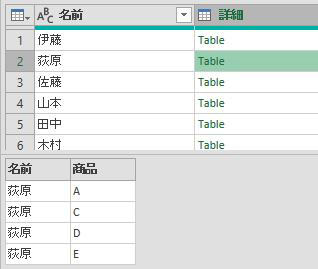
次はグループ毎に、上の画像の商品列の内容をリスト化します
カスタム列の追加
前述のグループ毎にリスト化するには、カスタム列・作成画面を開くところから始めます
カスタム列・作成画面で、次の画面のように詳細列を指定すると、過去の記事の通りグループ毎にテーブルが作成されます
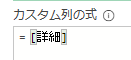
次の画像の「詳細.1」列が、上の画像から出力されたカスタム列の内容です
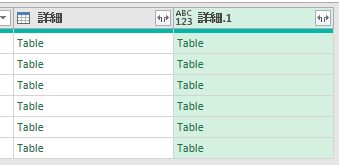
今回はテーブルではなく、各テーブル内の商品リストを出力します
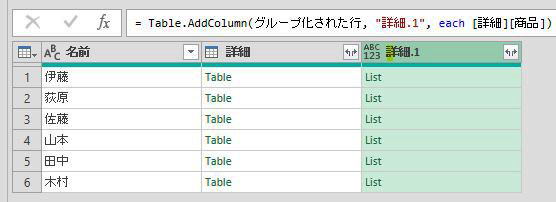
リストを出力するには、カスタム列・作成画面にて次の画像のようにリストになる列を加えます

これで、商品リストが各テーブル毎に出力されます
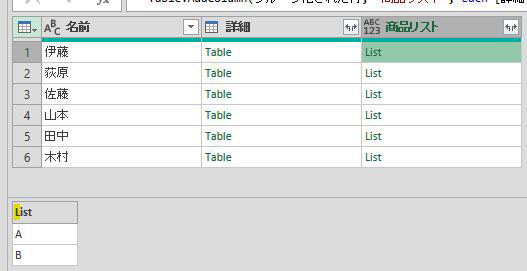
各リストにカーソルをあてると「リストの中味」が次の画像のように見れます
こちらを前述の「今回のポイント」にて紹介したように、「展開マーク」をクリックし、「値を抽出する」から1つのセルにリストを出力します
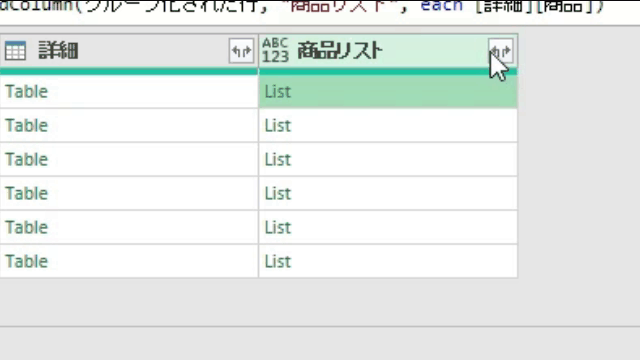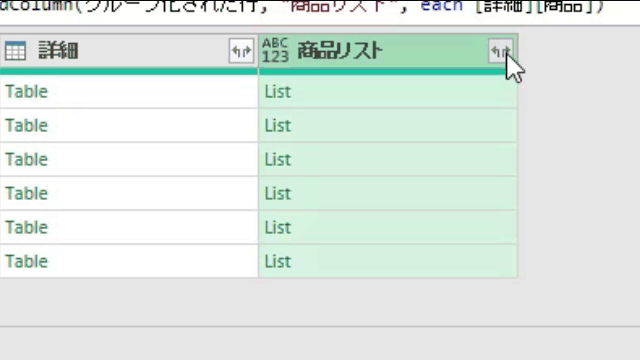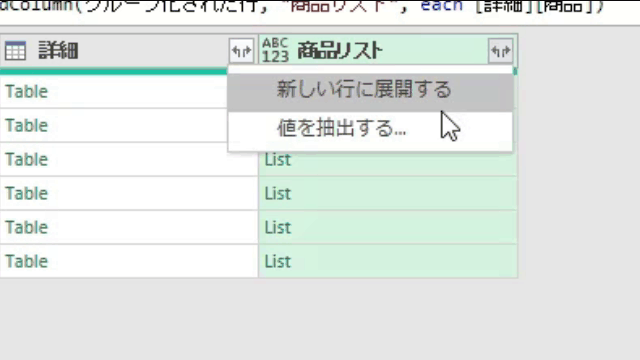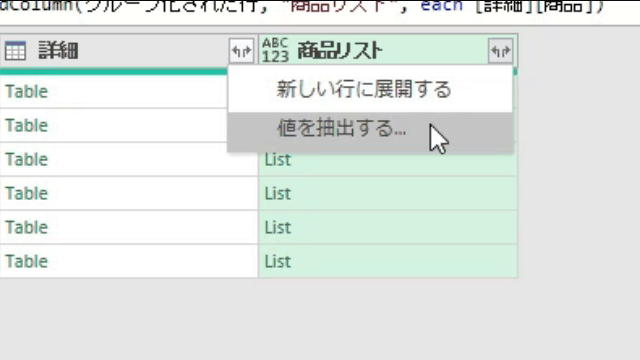
「値を抽出する」をクリックした後は次の画像のように、値を区切る記号を指定する画面が出てきますので、そちらで「記号」を指定してください
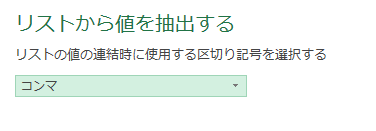
記号を指定したら、次の画像のようにグループ毎に1つのセルにリストが出力されています
応用編
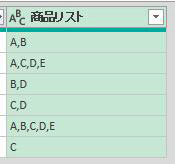
仮に変換対象のデータが1列のケースも解説します
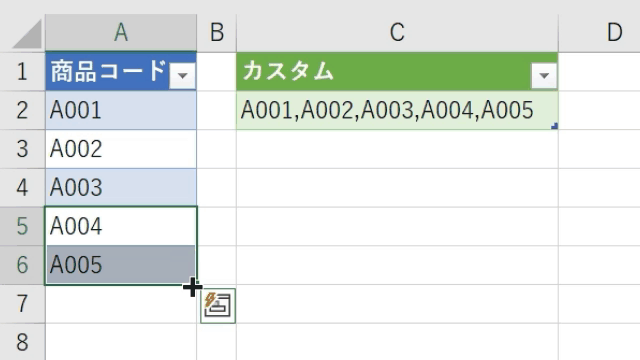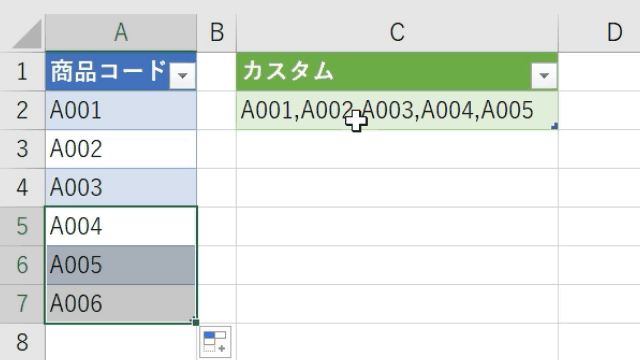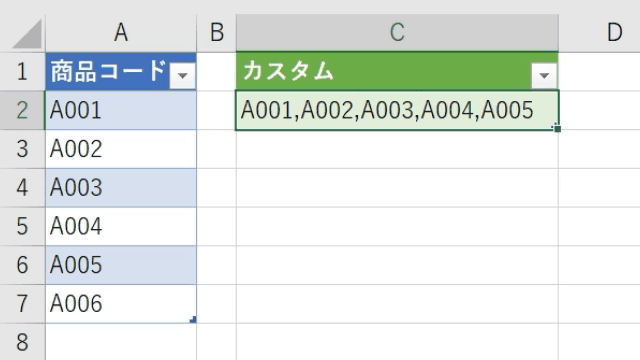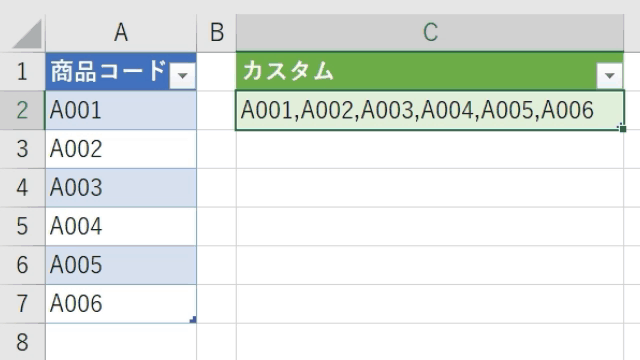
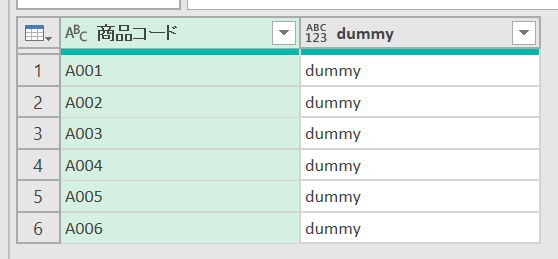
この場合は、一旦、カスタム列作成画面で「ダミー列」を追加します

こうすることで「グループ化」機能を前述のようにうまく活用することができます
<まとめ>
今回は複数の行の内容を、1つのセルに出力する方法を解説しました
ポイントは2つあり、まず1つ目はグループ化において「すべての行」を指定することです
この「すべての行」を指定すると、グループ毎にテーブルが作成されます
グループ毎にテーブルを作成したら、「カスタム列・作成画面」にて各テーブルからリストを作成しておきます
2つ目のポイントは、各リストの内容を「値を抽出する」機能にて1つのセルにリストを出力することです
今回紹介した方法は、それほど使用頻度は高くないと思います
ただ、今回の内容は、M言語の重要概念であるテーブルとリストを体感するのにいい内容だったと思います
特にグループ化において、「すべての行」を指定してグループ毎にテーブルを作成するパターンは色々と応用できそうです!
ぜひ、実際に手を動かしてみて試してみてください
記事を最後まで見て頂き誠にありがとうございました
参考までに今回使用したファイルを添付します
次回は、M関数のText関数について2つ事例を紹介します