【M言語は難しくない!】M言語への理解を深めて、Power Queryの「まだ触れたことのない便利機能」を有効活用できるようになりましょう!!
https://youtu.be/HMcsg_B-gm0
パワークエリは直感的なクリック操作で一括処理が行えるのが大きなメリットです。ところが、エクセルシート上では簡単に行えていた「セル単位での操作」や、「別シートの参照」、「関数を組み合わせた処理/ネスト」に相当する処理が行えません
要は、Power Queryエディタ内のメニューにある、行列単位の一括処理しか行えないのです
Power Queryエディタ内のメニューにある処理以外の事をしようとすると、M言語の領域にまで踏み込むしかありません
ところが、詳細エディタや数式バーを見ると、小難しそうなコードが並んでいます
M言語は一見、取っ付き難いのは確かです
但し、特定のルールや使用パターンさえ押さえてしまえば、実はそんなに難しくないはずです
まずは簡単な例にて、M言語を活用することが必ずしも難しくないことを紹介したいと思います
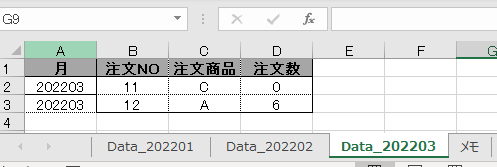
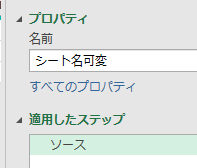
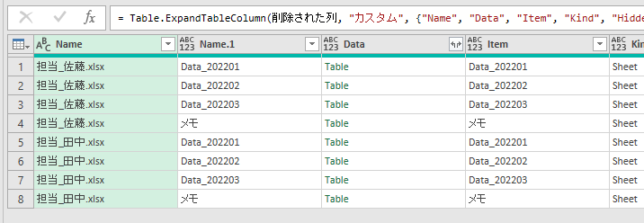
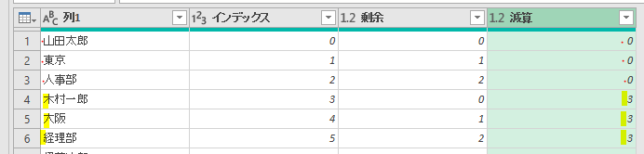
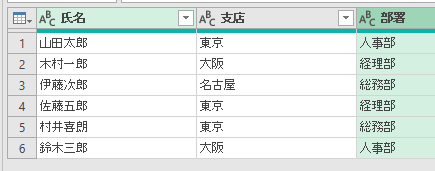
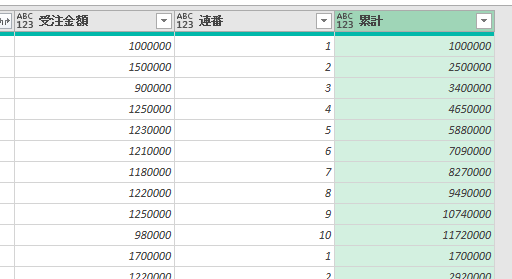
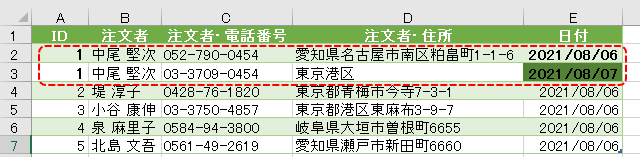
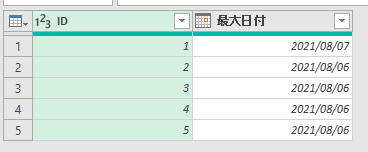
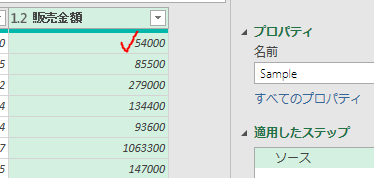
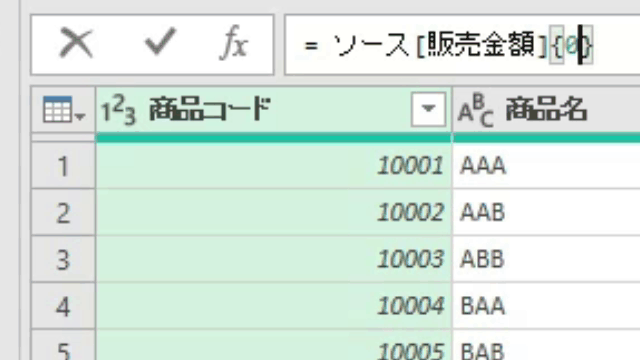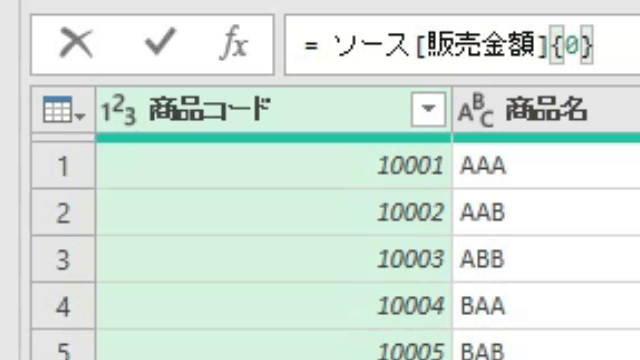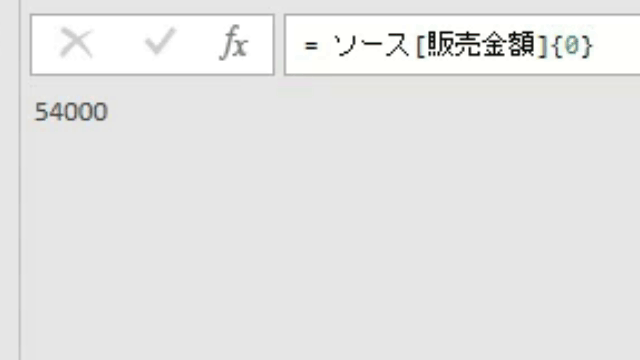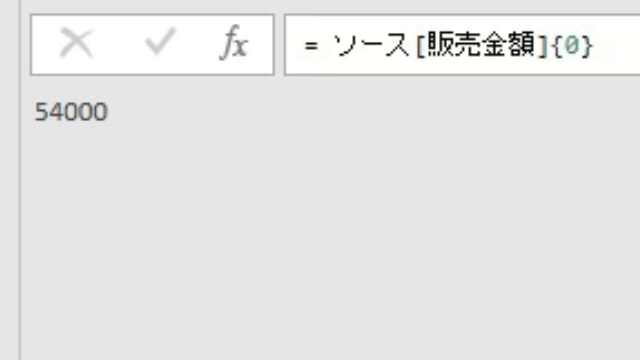
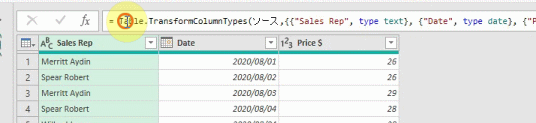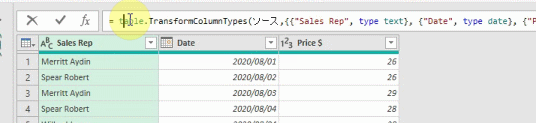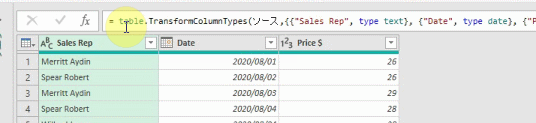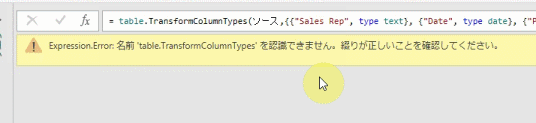
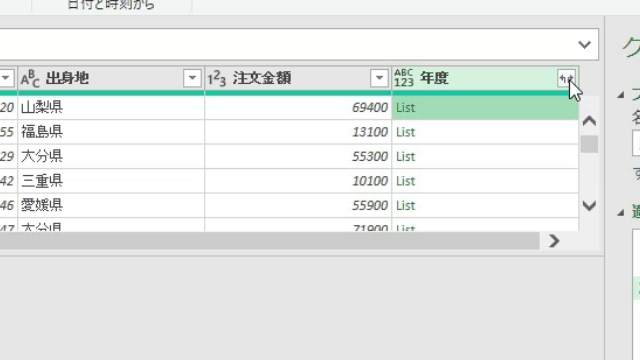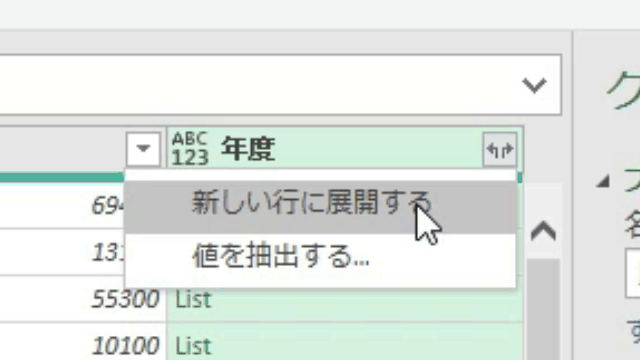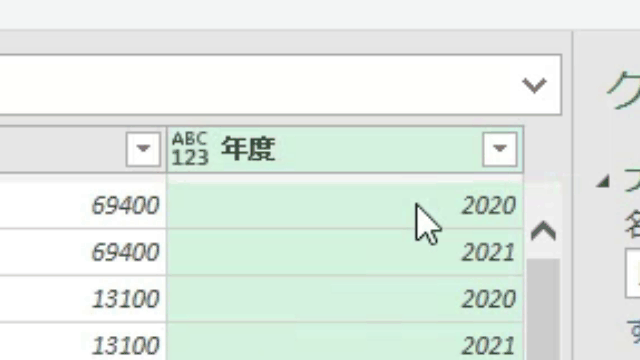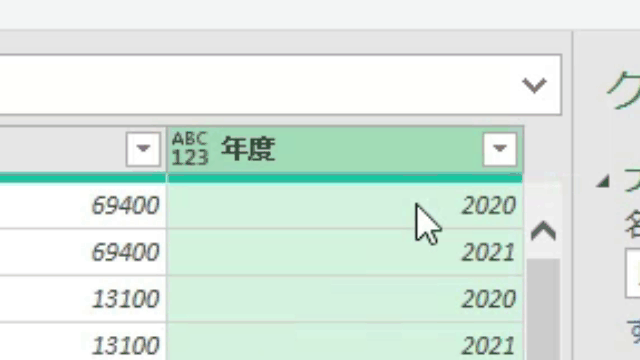
下の画像は、あるクエリのPower Queryエディタ内の画像です
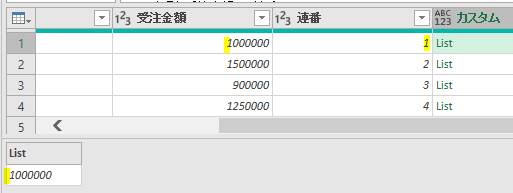
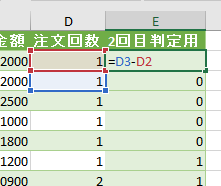
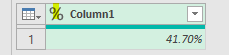
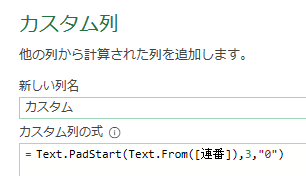
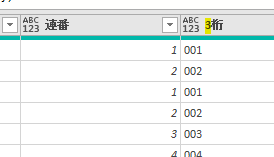
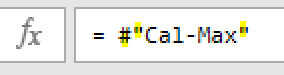
このエディタ内で<赤印の「販売金額」列の1行目の「54000」>の箇所を抽出してみます
エクセルシート上で言えば、「=セル名(例:A9など)」を数式バーに入れる処理です
ちなみに適用したステップには、まだ1つのステップ「ソース」しかありません
この場合、値の抽出は数式バーに簡単な1行を入れるだけで行えます
下のGIF画像の数式バーに注目してください!
=ステップ名[列名]{行位置}という単純なコードを入力しただけです
但し、「コード内の角括弧:[]と波括弧:{}の使い方のルールが分からないと小難しく感じてしまう」ただそれだけなのです
逆に、[]と{}の意味が分かるだけでも「かなりのことが行えそう!」と感じませんか?
少し種明かしをすると、[]がセル名のA列やB列に相当するものです
{}が「A9セル」や「B2セル」の行番号に相当するものです
そしてコード内のステップ名が、セル名の前に!を伴って付くシート名(例:平均値の計算!A2)みたいなものです
ルールやパターンが分かれば、エクセルシート上での処理とそれほど違いはないのです
この回では、M言語に慣れるためのウォーミングアップとして、M言語の特徴を3つに絞り解説します
そして、最後にPower Queryの「まだ触れたことのない便利機能」の事例を1点解説します
今回解説する「まだ触れたことのない便利機能」 の便利さを肌で理解した時には、「M言語理解へのハードル」が確実に少し下がっているはずです
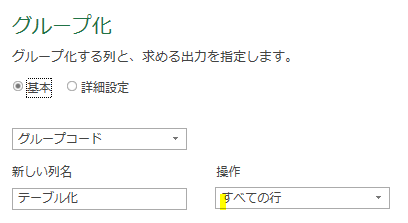
1.コードのカラー
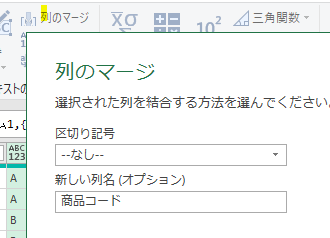
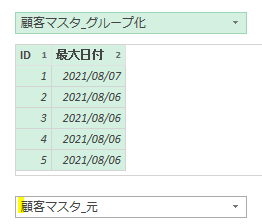
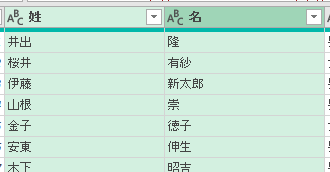
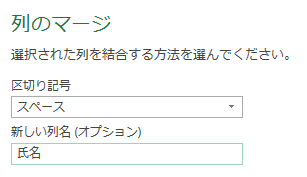
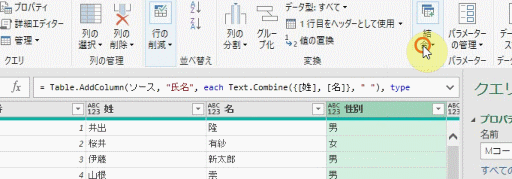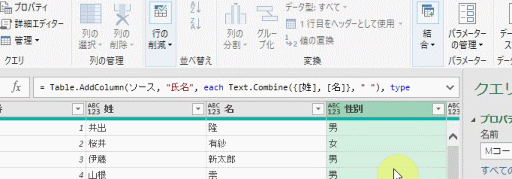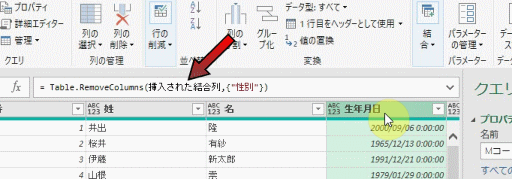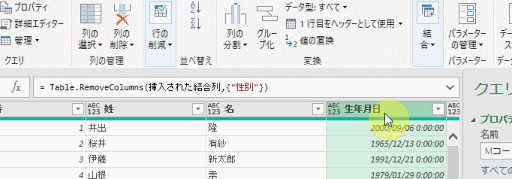
まず、Power Queryエディタ(以降、エディタ)で「列のマージ」をしてみます
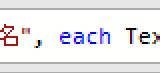
マージする内容は、下の画像の「姓」と「名」です
「姓」と「名」の間には、スペースを入れます
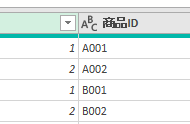
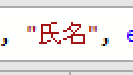
すると、数式バーが次のような表示になります

上の画像には、黒を除いた「3色」が含まれています
この3色にはそれぞれ意味があります
①赤➡文字列
列をマージする際に、新しく追加される列の「列名」として指定した文字列「氏名」が赤色になっています
②青➡システム予約語
後の回で、個々の用語の意味などは詳細を解説しますが、「each」や「type」などが青色になっています
これらは「システム予約語」と言われるものです
他に「if」「else」なども該当します
システム予約語は、システム言語として、予め使用することが決まっている用語です
③緑➡ハードコード(自動記録)された値
こちらは、エディタ内でステップを追加した際に、ハードコード(自動記録)された値です
上の画像は、列をマージした時、自動的にデータ形式が「文字列」として自動記録されたことを表しています
2.大文字と小文字の区別
M言語を扱う際に、意識しておかなくてはならないことの一つとして「大文字と小文字」の区別があります
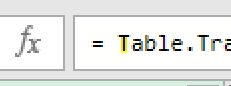
仮に、下の画像の「T」を小文字の「t」に置き換えてみます
すると、下のGIF画像のようにエラーになります
M言語を扱う際には、大文字と小文字の区別は特に意識しましょう!
3.ステップの引継ぎ
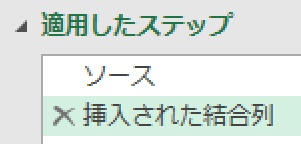
前述の1.で列のマージを行ったエディタ内には、下の画像のように2つの適用したステップがあるものとして以降の解説を行います
上の画像の2つ目のステップ「挿入された結合列」の数式バーの表示には、「ソース」という名前があるのが確認できます
では、3つ目のステップとして、既存の列を削除したらどうなるでしょうか?
3つ目のステップの中には、2つ目のステップの名前「挿入された結合列」が含まれています
つまり、各適用したステップは、前のステップ名を通じ、基本的には<一つ前ステップの内容>を自動的に引き継いでいきます
4.参照ステップ作成
前述の3.ではエディタ内で<一つ前のステップの内容>を自動的に引き継ぐというPower Queryの特徴について解説しました
但し、これはあくまでも”基本的には”、”自動的には”という話しであり、前ステップをスキップして参照することもできます
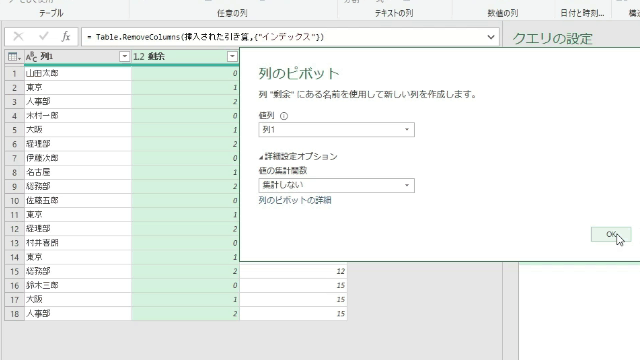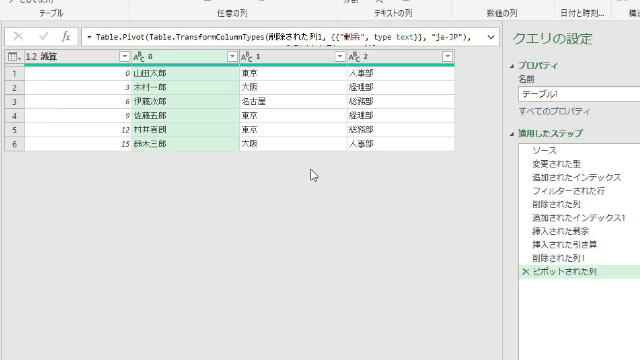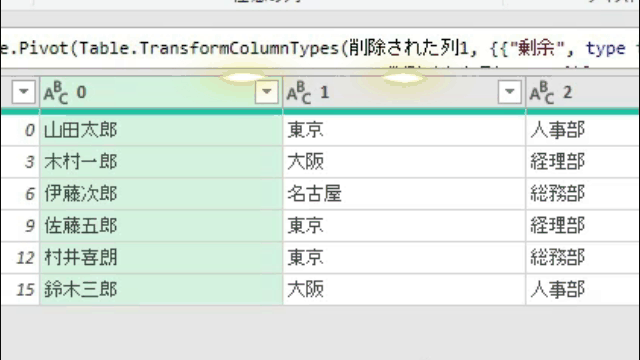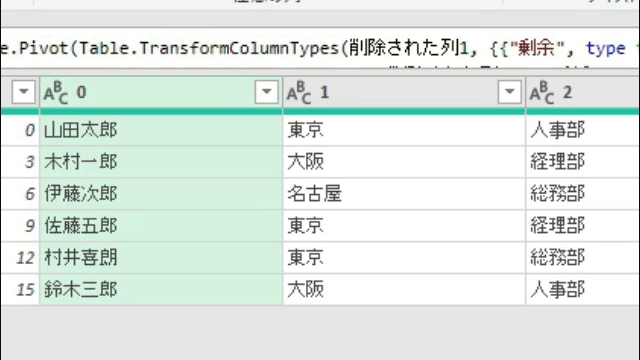
では、この「参照のスキップ」を利用した、新たな数字の集計方法を紹介します
エディタ内の話しに戻り、一つステップを追加します
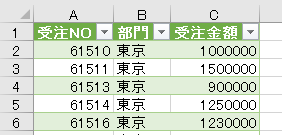
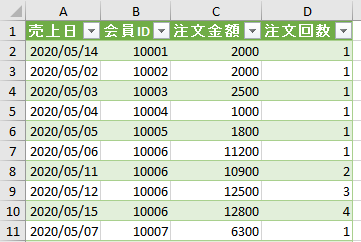
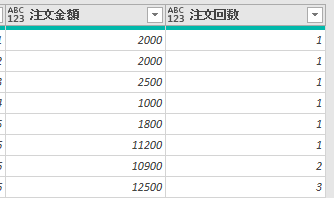
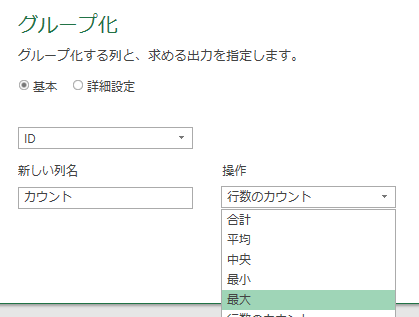
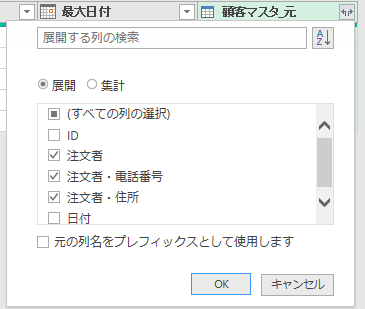
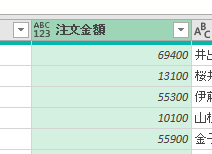
上の画像の「注文金額」の列から全体平均を算出します
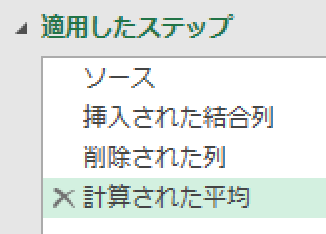
すると下の画像のように、「削除された列」ステップを引き継いだ「計算された平均」というステップが追加されます
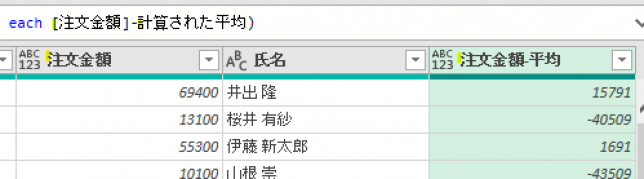
この「計算された平均」で算出した値「53609」を、他のステップで参照して活用できるようにします
この、他のステップで参照できるようにしたステップを、以降「参照ステップ」と呼ぶことにします
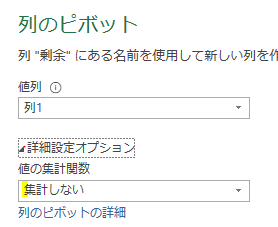
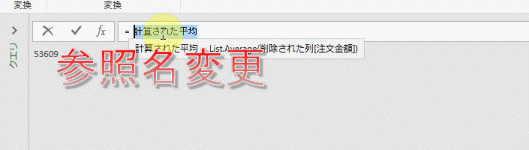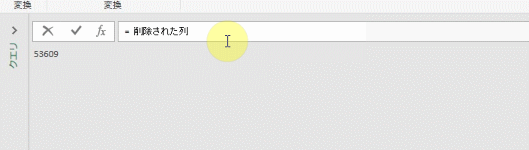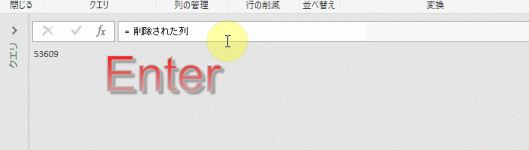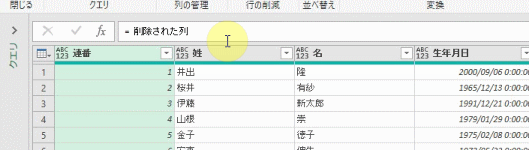
では、この「計算された平均」ステップを「参照ステップ」として確定するための処理を数式バーで行います
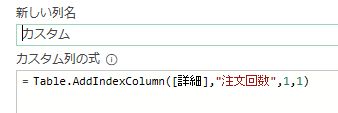
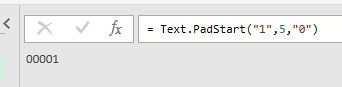
下のGIF画像のように「関数のマーク」を左クリックすると、新たなステップが追加されます
「カスタム1」というステップが新たに追加されましたが、このステップはある種、ダミーのステップです
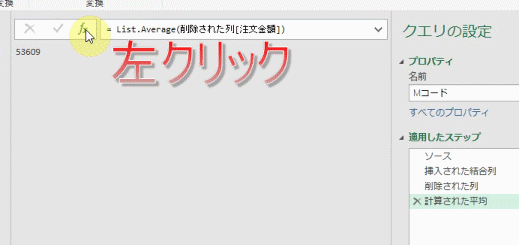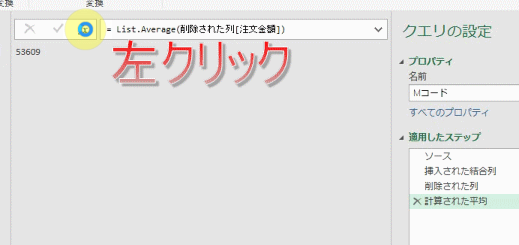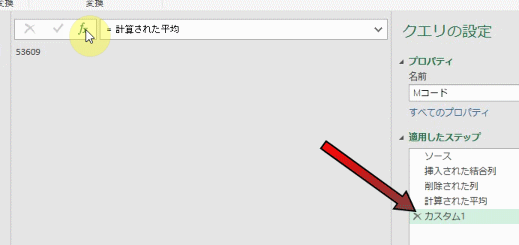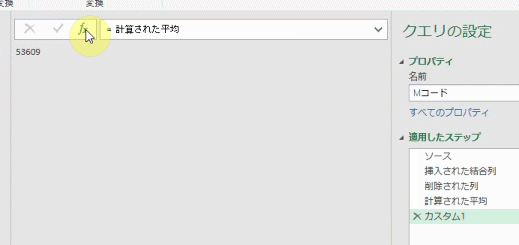
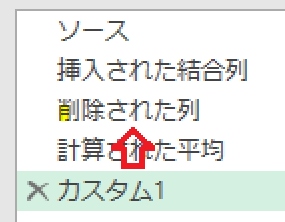
更にこのステップから、下の図のように「前のステップ」をスキップして「削除された列」ステップを参照します
前のステップをスキップして参照するには、下のGIF画像のように数式バーでステップ名「削除された列」を入力し、Enterを押します
すると、エディタの画面が「削除された列ステップ」の内容になります
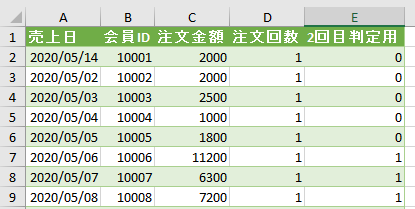
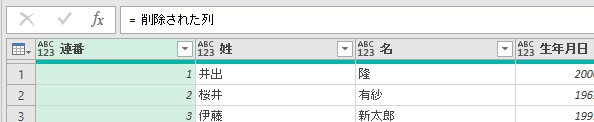
エディタ画面からは下の画像の「平均金額」は消えましたが、これで「平均金額」を他の画面で参照して活用できるようになりました
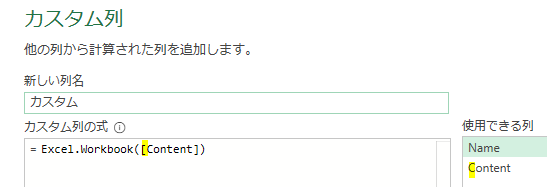
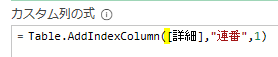
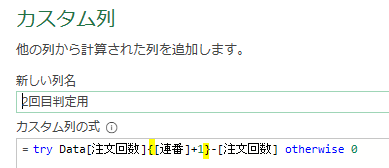
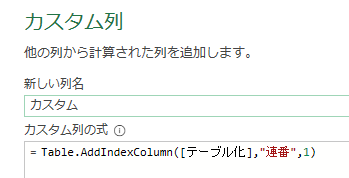
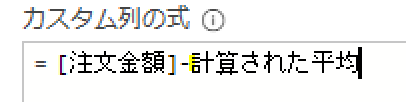
今回は、「平均金額」を参照ステップとして活用したカスタム列を作成してみます
作成する内容は「個々の注文金額-平均」です
注文金額については、カスタム列作成の右側から挿入できます
 「
「
「平均」については、前述のステップ名「計算された平均」を参照します
つまり、「計算された平均」ステップで算出された「53609」が「注文金額」から差し引かれます
カスタム列を作成した後のエディタ画面は、次の画像のようになります
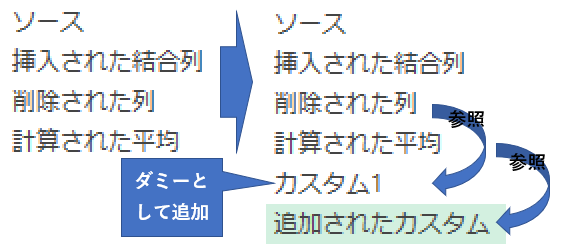
このカスタム列を作成するまでに、ステップを新たに追加したり、ステップをスキップしたりしたので、図で整理して今回の処理を振り返ります
ⅰ)カスタム1の列をダミーとして追加
この処理で追加されたステップにより、「計算された平均」ステップを残したまま、エディタ画面を「削除された列」ステップの画面に戻せています
つまり、「削除された列」➡「計算された平均」というステップの順序が、「計算された平均」➡「削除された列」という順序に変えることができました
ⅱ)カスタム列の作成
ⅰ)で変えた順序を活かして、個々の注文金額マイナス全体の平均を計算します
<まとめ>
今回は「M言語に慣れる」の1回目として、M言語の特徴を3つに絞って解説しました
1.コードのカラー
2.大文字と小文字の区別
3.ステップの引継ぎ
上の3つを意識してPower Queryを活用してもらえると、M言語が必ずしも難解なわけではないことが、分かって頂けると思います
そして、3つの特徴の後には3.ステップの引継ぎを応用した「参照ステップ」について解説しました
こちらでは、ステップの順序を入れ替えて「ステップで算出した値」を有効活用できるようにしました
ⅰ)一旦、注文金額の平均値を計算➡参照ステップ
ⅱ)カスタム列・作成画面で「各行の注文金額-平均値/参照ステップ」を計算
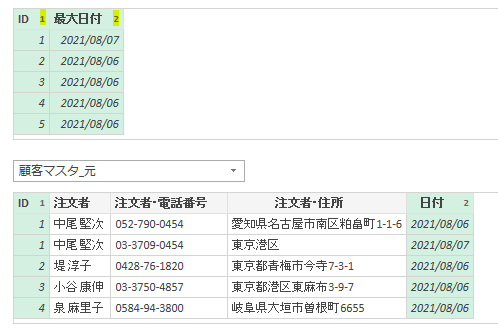
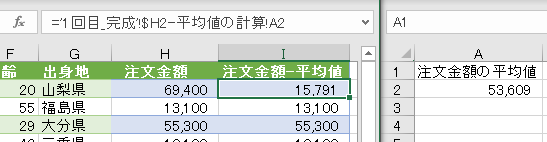
この上のⅰ)ⅱ)の処理はエクセルシート上で例えるなら、以下の画像のような処理です
データが存在するシート/画像左とは別のシート/画像右で平均値を計算しておき、元のデータが存在するシートで注文金額から平均値を引いています
ですので、今回使用した参照ステップの値はエクセルシートでの操作でいえば別シートでの計算です
M言語を使用していけば上の事例と同じ様に、エクセルシート上での細かい操作に近いことが一括で行えることが理解できてきたと思います
では、次回からはM言語を有効活用してPower Queryの魅力を新たに引き出す方法について、もっと具体的に解説していきます
M言語の記事一覧については、ここから見ることができます
記事を最後までお読み下さり、誠にありがとうございました
参考までに解説に使用したエクセルファイルを添付します


にほんブログ村