
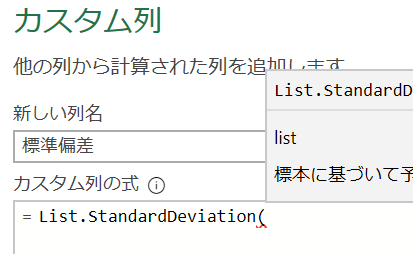
【数字は平均だけではよく分かりません。グループ化機能を更に深堀し、分析用の列に標準偏差も加えましょう!】 グループ化機能はとても便利です!グループ毎の集計を簡単に行いつつ、集計した数値を並べることができます 但し、グルー…

こちらのコーナーでは、DAX関数*をうまく使うためのコツを解説します *エクセルのワークシートでは関数に相当するもの フィルター評価と行評価 フィルター評価 Power BIのレポート画面では常にフィルター評価の影響を受…
先日ある方から大量の商品データの中から、価格違いの設定が起こっているところを見つけたいという依頼がありました またルールがあり、同じ素材/同グループであれば販売する色種類が違っていても同じ価格で設定しなければいけないとい…
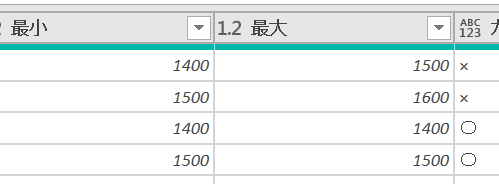
ピボットテーブルのグループ化機能を使うと、数字が見やすくなるため重宝しておりますが、Power BIでも同じようなことが行えます 今回は、Power BIにおけるグループ化機能を量/ヒストグラムと質に分けて解説します 分…
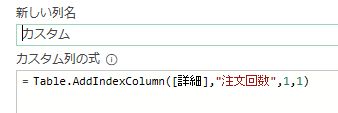
パワークエリはとても便利ですが、M言語となると使い道がよく分からないと思います 今回は、M言語を使用した実践的な分析手法を紹介したいと思います 私は以前、EC通販会社に勤めていました EC通販では顧客の顔が見えないの…

パワークエリの「クエリのマージ機能」はとても便利で、エクセル関数のVLOOKUP関数より使いやすいです 「クエリのマージ機能」を有効活用すれば、参照表(マスタデータ)の活用もかなり手軽に行えます 今回の記事では、「クエ…

RFM分析は顧客を3つの指標で分類して、顧客別に施策を講じる手法です Recency いつ?、Frequency 頻度?、Monetary いくら? 今回…
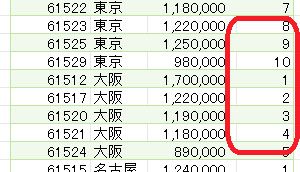
【M言語は難しくない】今回はデータをグループ化した際に、1から始まる連番をグループ毎に作成する方法について解説します。この処理の仕方を覚えると、エクセルの使い方の幅が広がります コードの採番や顧客の2回目のリピート状況把…
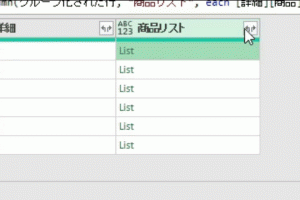
【M言語は難しくない】今回は複数行に拡散している値を、次のGIF画像のように「記号」をつなぎ目にして、1つのセルにまとめます 今回のポイント 今回のポイントは2つあります 1つ目は過去記事で紹介した「すべての行」によるグ…

ガッツ鶴岡/Gutsy Tsuruoka
┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘
プロから教わるビジネス講座・ウェブ講座が1,000円から!
初心者歓迎、1回から気軽に学べる日本最大級のまなびのマーケット「ストアカ」に今すぐ登録!!
https://px.a8.net/svt/ejp?a8mat=3BSKJM+28YZTM+352U+6BMG3
┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘
![]()


最近のコメント