Power QueryにAIを直接利用する~実はPower Queryはコードでできている~
【使い方は多数!Power QueryのコードをAIに直接書いてもらおう!】 読者の方の中にはエクセルマクロのVBAコードや関数をAIに書いてもらっている方もいらっしゃると思います 但し、Power Queryの場合、A…

【使い方は多数!Power QueryのコードをAIに直接書いてもらおう!】 読者の方の中にはエクセルマクロのVBAコードや関数をAIに書いてもらっている方もいらっしゃると思います 但し、Power Queryの場合、A…
【列の削除や列の並び替えをスムースに行うための技術を解説します】 Power Queryを使用していてよく困るのは、1画面では収まらないほど大量に列があるケースでの「列処理」です 残す列を選択したり、列を並び変えたり…
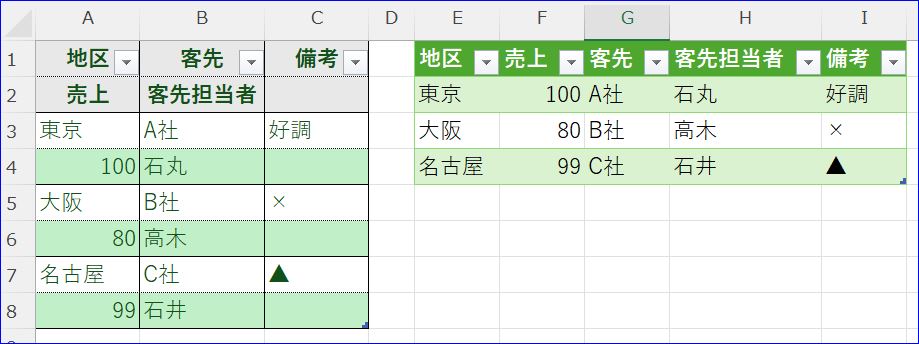
【奇怪な2行1組のデータもパワークエリの技術の組み合わせでテーブル形式にできます】 稀にですが、見出しだけでなくデータ行も下の画像のように2行になっている表を見ることがあります セル結合により行列ともに2段になっている表…
【取得するファイルを自動で可変にする、究極のPower Query術です!】 この記事を見ている読者の方の中には、毎日システムから出力されるファイルを処理しているという方もいらっしゃると思います この場合、Power Q…
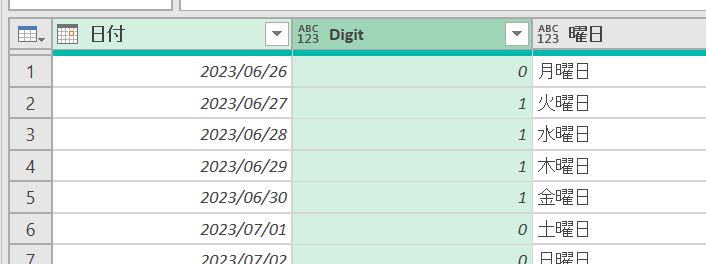
【M言語独自のリスト作成を通じて、経過営業日を自由自在に算出する】 エクセルのワークシートには経過営業日を計算してくれる便利な関数があります。Power Queryではその手の関数はないですが、独自のカレンダーテーブル活…
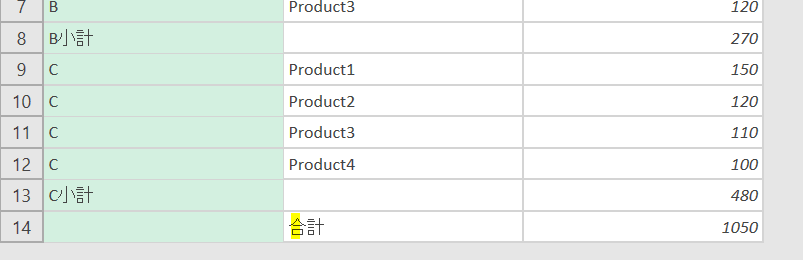
【通常は一律で処理するPower Queryですが、M関数を使えば小計と合計を列に追加・挿入することができます】 M関数をうまく活用することで、通常では考えられないような表を作成することができます 今回は上のGIF画像の…
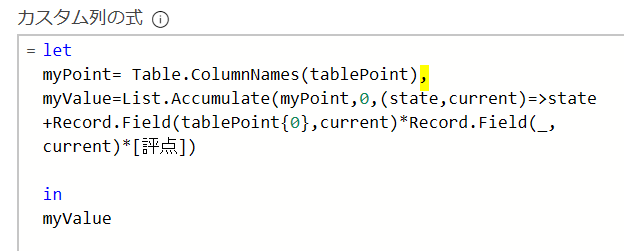
【M関数を利用することで、数式の修正しなくても列数が可変の表を組み合わせて計算できるようにします】 値を別表で作成した上で計算を行うケースはよくあると思います 上の画像のケースでは、ボーナスを計算するのに基礎となる評点を…
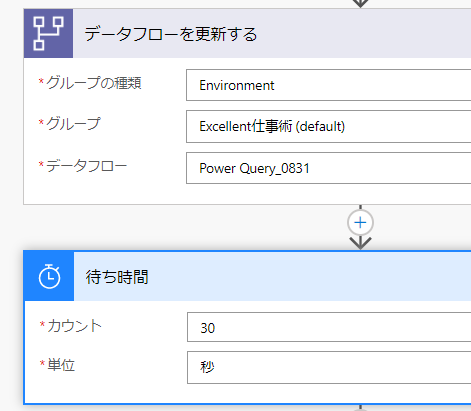
【Power QueryをOneDriveなどのクラウドのエクセルでうまく活用する方法を解説します!】 クラウドがビジネスの主戦場になってきた今、Power Queryをクラウドでうまく活用できないか?という声を最近聞く…

前回の続きで、パワークエリを使用して行だけでなく列についても、値の変更もあわせて変更箇所を特定できるようにしたいと思います ポイント 2つの表を結合するのは前回と一緒です 今回はピボット解除を行い、複合キーを作ったうえで…
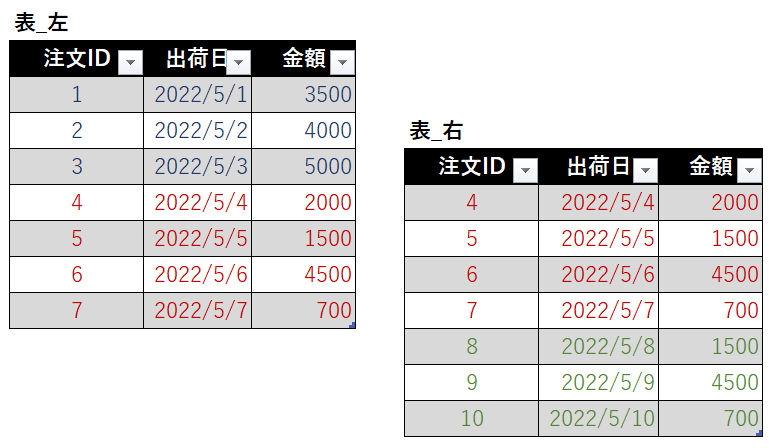
2つの表の間でどの行が追加されているのか?削除されているのか?を適時確認・集計できるととても便利です 受注のキャンセルデータの管理やミスの発見など、2つの表の適時確認・集計の活用の場はかなり広いです Power Quer…

ガッツ鶴岡/Gutsy Tsuruoka



最近のコメント