クエリの関数化事例~複数シートを一括で編集する
【一度作成したクエリを関数化して複数シートに使いまわし、結果的に一括処理する】 エクセルファイル内で複数シートに分かれていると、一括処理ができなくて困ることがあります 一番、困るのは各シートにヘッダーデータがあるようなケ…
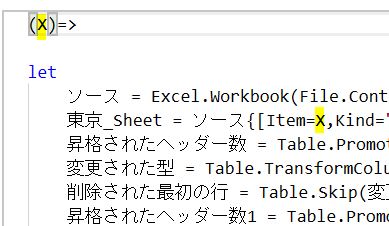
【一度作成したクエリを関数化して複数シートに使いまわし、結果的に一括処理する】 エクセルファイル内で複数シートに分かれていると、一括処理ができなくて困ることがあります 一番、困るのは各シートにヘッダーデータがあるようなケ…
IF式は便利ですが、作成後のメンテナンスが大変だったりします 1つ内容を追加するだけでも、or以降のコードを追加しなくてはなりません 今回は、リストを使ってIF式の作成を簡略化する方法と、IF式自体を列に置き換える方法を…

以前、出現する特定文字の上の行を可変で削除する方法は過去の記事で紹介しました 今回は「特定文字の下」を削除する方法を解説したいと思います 上の画像に「部門」という文字が出現しますが、こちらの文字以降の行を可変で削除します…

どうしてもクエリが長くなってしまい、後で見返しても内容がよくわからず困っているという声をよく聞きます 今回は、M関数の書き方を工夫してステップ数を削減する「ちょいテク」を紹介します カスタム列の追加時 カスタム関数を追加…
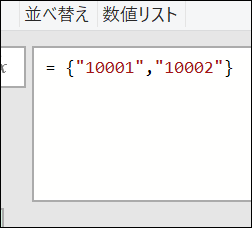
【Power Queryのパラメーターの仕組みを使い、複数のファイルから特定のシートのデータを可変で取得しよう】 Power Queryのフォルダにある複数ファイルから一括でデータを取得する仕組みは驚くほど便利です この…
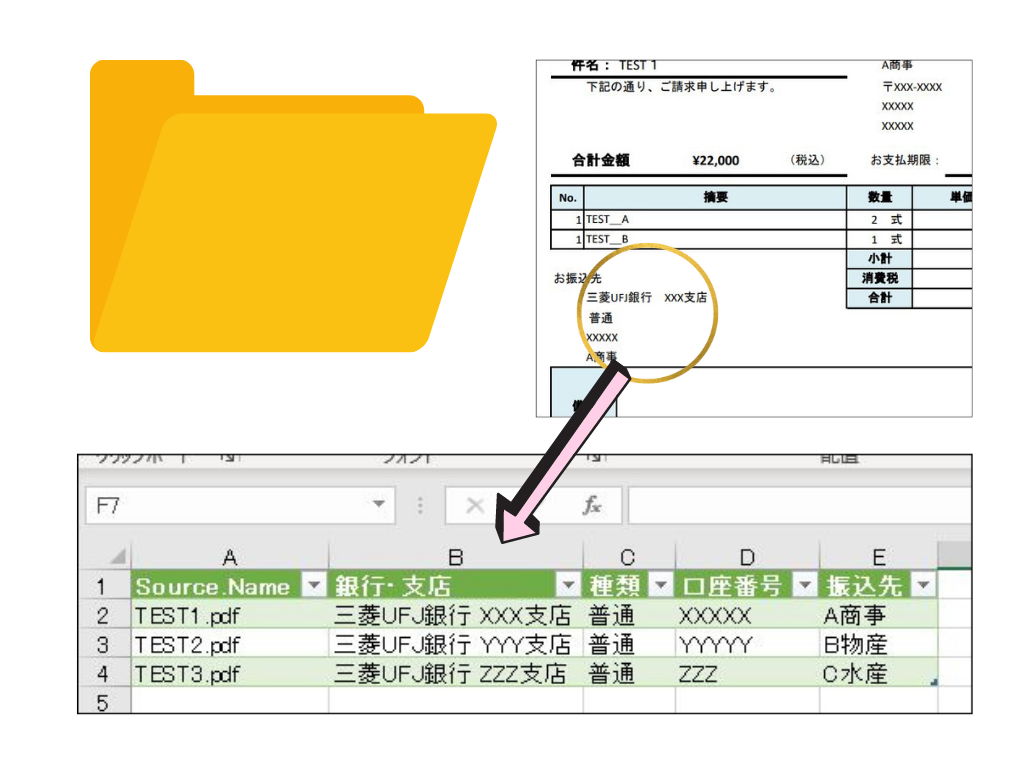
今回はフォルダに入れた複数PDFファイルから、一部の箇所だけデータを一括で取得します 扱うPDFファイルには、以下の画像のように振込先のデータが含まれています このPDFファイルから振込先のデータだけを取得します しかも…
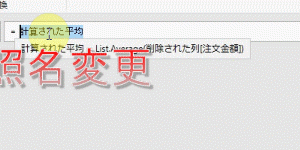
【M言語は難しくない!】M言語への理解を深めて、Power Queryの「まだ触れたことのない便利機能」を有効活用できるようになりましょう!! パワークエリは直感的なクリック操作で一括処理が行えるのが大きなメリットです…

【M言語は難しくない!】今回は、前回紹介したM言語の特徴を意識しながら、実際に「M関数」を使用したカスタム列を作成してみましょう! では、前回紹介したM言語の特徴を振り返ってみましょう! ⅰ.コードのカラー 赤は「文字列…
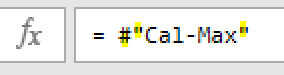
【M言語は難しくない!】今回は、数式バーを編集して「ダイナミックフィルタリング」を行ってみましょう!。ここで言う「ダイナミックフィルタリング」とはフィルタリングの値を固定せず、元データの追加や修正に応じてフィルタリングの…
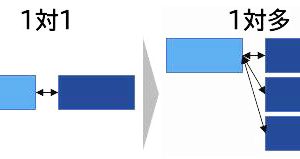
【M言語は難しくない!】今回はカスタム列の隠れた裏技を使用して、特殊なテンプレートを作成します。今回は次の画像のように、「1対多」の関係の結合を「コードを1つ追加する」だけでサクッと行います この処理は、従来であればVB…

ガッツ鶴岡/Gutsy Tsuruoka



最近のコメント