複数グループ内で値違いの箇所を見つける~グループ化の応用~
先日ある方から大量の商品データの中から、価格違いの設定が起こっているところを見つけたいという依頼がありました またルールがあり、同じ素材/同グループであれば販売する色種類が違っていても同じ価格で設定しなければいけないとい…
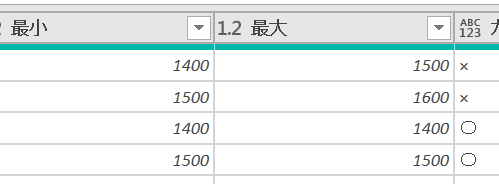
先日ある方から大量の商品データの中から、価格違いの設定が起こっているところを見つけたいという依頼がありました またルールがあり、同じ素材/同グループであれば販売する色種類が違っていても同じ価格で設定しなければいけないとい…
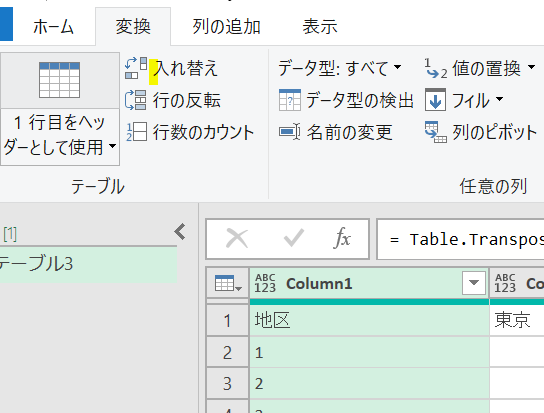
【列方向ではフィルターは行えないと思っていませんか?実は3クリックをプラスすれば可能です】 Power Queryエディタ画面にて、空欄だけの列は処理したくない・と思ったことはありませんか? 実は「ヘッダーの上げ下げ」と…
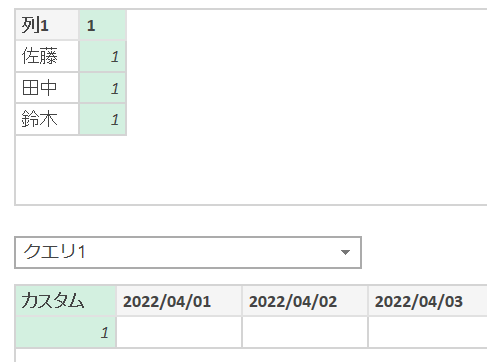
Power BIやPower Pivotではタイムテーブルの活用が欠かせません。ただPower Queryでもタイムターブルの作成と活用を行うことができます。今回の記事ではPower Queryならではのタイムテーブルの…
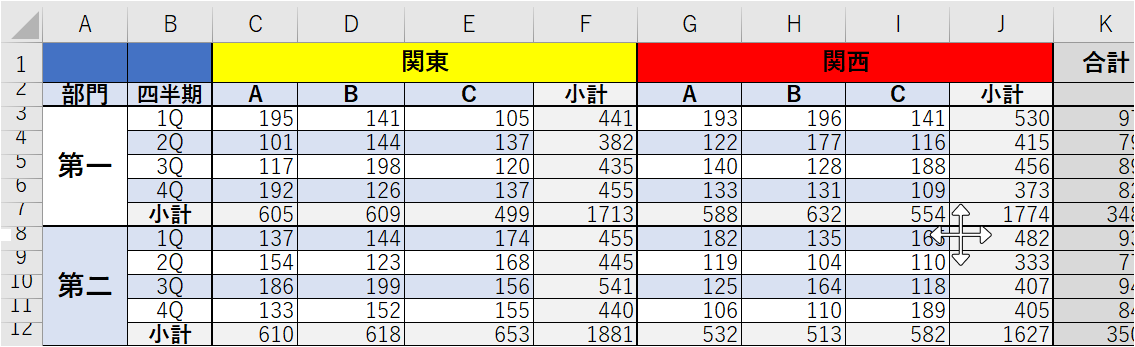
読者の皆さんも見やすくするためにセル結合を組み合わせた、下の画像のような表をみたことがありますよね!こちらの表をPower Queryの基礎技術を組み合わせてテーブル形式にしましょう! この手の表は見た目がよさそうな気が…
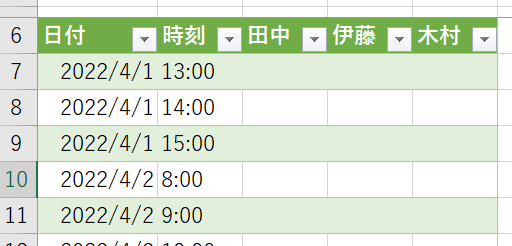
今回は、開始時間・終了時間・担当者を可変で指定できる月間スケジュール表(記入用)を、Power QueryのM言語の技術をフル活用して作成します 4月1日であれば、13時から15時まで1時間刻みで行が自動で用意されます…
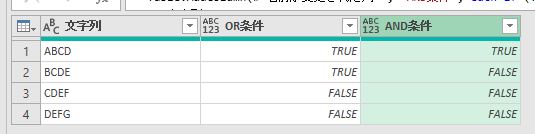
【IF式の中にOR条件とAND条件を組み入れて、条件式をうまく構築しよう】 Power Queryのカスタム列ではIF式を活用することができます 過去の記事でも紹介しましたが、IF式を複数ネストすることもできます 今回の…

【割り算の余りの算出とピボット機能をうまく使ってVBAと同等の処理を行ってみましょう】 今回は下の画像のように1列のデータから、画像右側のようなテーブルデータを作成してみます ポイント ポイントは1列のデータの中で、何行…

過去2回の記事でM言語を実践的に活用する事例を紹介しました この2回の記事で共通するのは「グループ毎に連番を付与」する技術を使用していることです 今回も「グループ毎に連番を付与」する技術を有効活用して、グループ毎に累計を…
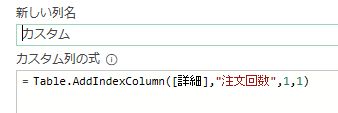
パワークエリはとても便利ですが、M言語となると使い道がよく分からないと思います 今回は、M言語を使用した実践的な分析手法を紹介したいと思います 私は以前、EC通販会社に勤めていました EC通販では顧客の顔が見えないの…
パワークエリはとても便利です。利用者もどんどん増えていると思います。ただ、パワークエリの言語のM言語となると「何ができるの?」となると思いますので、今回は実践での活用例を紹介したいと思います 今回は下の画像の表にある商…

ガッツ鶴岡/Gutsy Tsuruoka



最近のコメント