Power Queryに強くなる~M言語/コードに慣れましょう~ 第10回
【Power Queryはあくまでコードでできています。これが今回のポイントです】 Power Queryはとても便利です。メニューをクリック操作していくだけでかなりのことができます 但し、メニュー操作に慣れてしまうと、…

【Power Queryはあくまでコードでできています。これが今回のポイントです】 Power Queryはとても便利です。メニューをクリック操作していくだけでかなりのことができます 但し、メニュー操作に慣れてしまうと、…
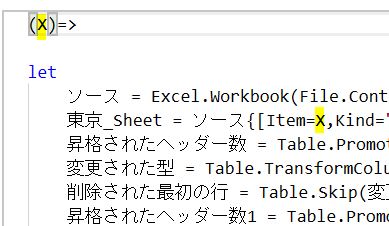
【一度作成したクエリを関数化して複数シートに使いまわし、結果的に一括処理する】 エクセルファイル内で複数シートに分かれていると、一括処理ができなくて困ることがあります 一番、困るのは各シートにヘッダーデータがあるようなケ…

昨年、Udemyにて「Power Queryのメニューにはない裏技ができる! M関数を学んで使えるようになる講座」をリリースしました。但し、多くの意見・指摘が寄せられたため今回、全面的に動画を撮り直しました この機会に無…
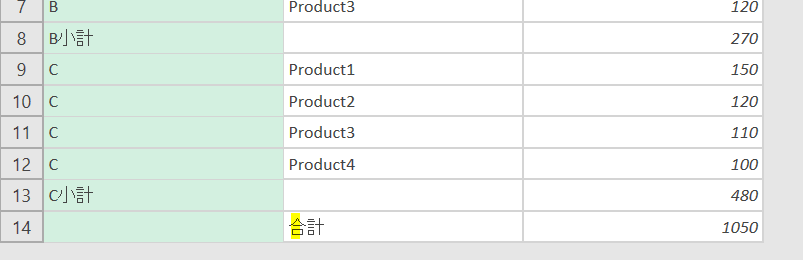
【通常は一律で処理するPower Queryですが、M関数を使えば小計と合計を列に追加・挿入することができます】 M関数をうまく活用することで、通常では考えられないような表を作成することができます 今回は上のGIF画像の…
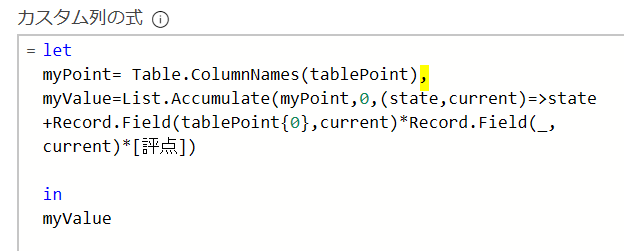
【M関数を利用することで、数式の修正しなくても列数が可変の表を組み合わせて計算できるようにします】 値を別表で作成した上で計算を行うケースはよくあると思います 上の画像のケースでは、ボーナスを計算するのに基礎となる評点を…
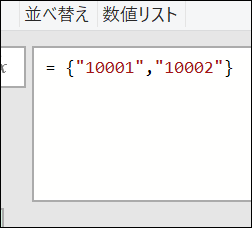
IF式は便利ですが、作成後のメンテナンスが大変だったりします 1つ内容を追加するだけでも、or以降のコードを追加しなくてはなりません 今回は、リストを使ってIF式の作成を簡略化する方法と、IF式自体を列に置き換える方法を…

以前、出現する特定文字の上の行を可変で削除する方法は過去の記事で紹介しました 今回は「特定文字の下」を削除する方法を解説したいと思います 上の画像に「部門」という文字が出現しますが、こちらの文字以降の行を可変で削除します…

どうしてもクエリが長くなってしまい、後で見返しても内容がよくわからず困っているという声をよく聞きます 今回は、M関数の書き方を工夫してステップ数を削減する「ちょいテク」を紹介します カスタム列の追加時 カスタム関数を追加…

昨日、リリース済みのUdemy動画コース「Power Queryを極めたい人必見!!M関数講座」の無料勉強会を開催しました 参加して頂いた皆様には感謝の一言です! 今後の動画コースの内容、並びに、Power Queryの…
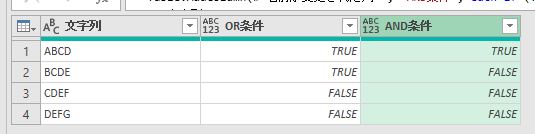
【IF式の中にOR条件とAND条件を組み入れて、条件式をうまく構築しよう】 Power Queryのカスタム列ではIF式を活用することができます 過去の記事でも紹介しましたが、IF式を複数ネストすることもできます 今回の…

ガッツ鶴岡/Gutsy Tsuruoka


最近のコメント