【CSVファイルを扱う基本パターンが分かれば、実はそれほど難解でもないです】
今回の記事ではPower AutomateのトリガーにてアップロードしたCSVファイルの内容を解析し、Sharepointリストに格納します
読者の方の中には「これの何が難しいの?」と思った方もいらっしゃると思いますので、次の画像を見てみてください

今回使用するCSVファイルをメモ帳で開いたものです
*使用するCSVファイルは、https://www.mhlw.go.jp/stf/covid-19/open-data.htmlから取得いたしました
エクセルで見かけるセルに格納されたデータではなく、データがカンマ区切りされながら繋がっています
もちろん、行や列はありません
こちらを今回の記事では、大きく分けて2段階でSharepointリストに格納できる、行や列にあるデータにします
1.改行コードを基にして、行がある構造にする
見出し改行コードAAA改行コードBBB改行コードCCC
⇒
見出し
AAA
BBB
CCC
2.見出しをスキップしてデータを抽出する
AAA
BBB
CCC
この2つをセットで行うのがCSVを変換する基本パターンです
今回の内容は本当に最低限の内容です
使用される文字コードの種類やCSVの中身の状況により、今回の記事に加えて追加処理が必要なケースもあります
但し、基本パターンを押さえておけばあまり混乱する必要はありません
では、詳細に処理を進めていきましょう!
ファイルのアップロード
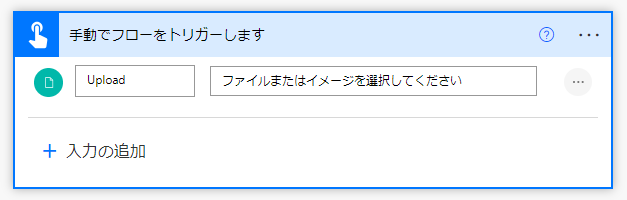
まずは手動でCSVファイルをアップロードします

入力ファイルの種類は「ファイル」を選択し、三点リーダーから必須に指定しましょう
base64ToString関数による変換
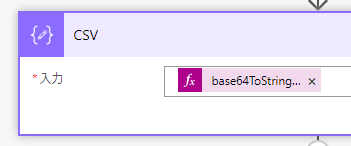
前述のアクションでアップロードしたファイルの内容だと実は全く読み取れない状態なので、データ操作コネクタを使って変換処理を行います
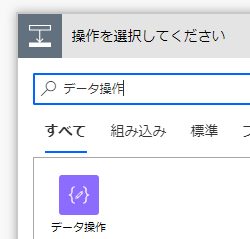
データ操作コネクタ内の「作成」アクションにて、Base64 ToString関数により人間が読み取れる形式にします
*Base64による変換はメールなどで行われる処理です。今回はBase64に変換されたものを再変換(デコード)する形になります
ちなみにBase64ToString関数による変換を行わないと、CSVファイルの内容は下の画像のような内容になっています
*Power Automateの実行履歴からトリガーの出力内容を一部スクショしたものです

ですので、あくまで機械同士でやり取りできる状態ということです
本題に戻り、Base64ToString関数での変換は以下のように行います
base64ToString(triggerBody()[‘file’][‘contentBytes’])
上の内容の関数の中身は「triggerBody()・・・」となっていて分かりにくいですが、要は動的コンテンツでトリガーの内容を指定したものです
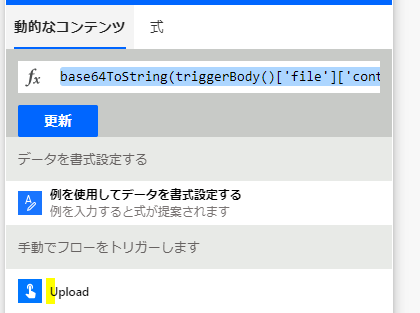
では、関数を作成したらフローを動かしてみて実行履歴の中身を見てみます
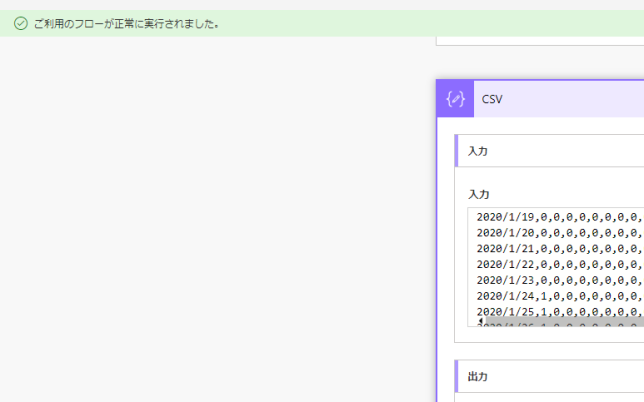
なんとか人間が読み込める形になっています
ちなみにデータ操作コネクタのアクションは名前の付け方に注意しましょう
後続処理で必ず参照しながら使用しますので、読みやすい名前を付けるように心がけましょう
Split関数による分割(改行)
こちらでは前述の次の処理をします
見出し改行コードAAA改行コードBBB改行コードCCC
⇒
見出し
AAA
BBB
CCC
こちらの分割処理を行うのにSplit関数を使用します
Split関数は2つの内容を引数に使用します
Split(分割するデータ,分割位置を指定する文字)
今回は分割位置を指定する文字として「改行コード」を指定します
改行コードについては、使われる文字コードに違っていたりするなど、詳細に説明しようとすると膨大な内容になります(私も残念ながら専門外です)
興味のある方は⇒こちらの外部記事もぜひご参照ください
本題に戻ります
今回、実際には次のようにSplit関数を指定します
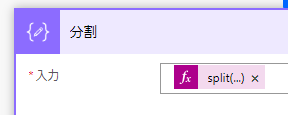
split(outputs(‘CSV’),decodeUriComponent(‘%0D%0A’))
第一引数は動的コンテンツの選択から前アクションを指定してください
第二引数は、改行コードをdecodeUriComponent関数で再変換したものを指定します
それでは、
ここまでの内容でフローを実行してみます
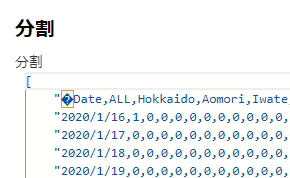
上記の画像のように、完全に行別に分割されています
見出しの1行をスキップ
今回はCSVの内容をSharepointリストに格納しますので、見出し列の内容は必要ありません
ですので、前述のように1行スキップする必要があります
スキップ処理には文字通り、skip関数を使用します
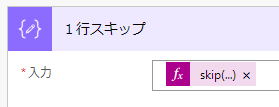
skip(outputs(‘分割’),1)
それではこれまでの内容でフローを実行してみましょう
下が今回、フローを動かしたときの画像です
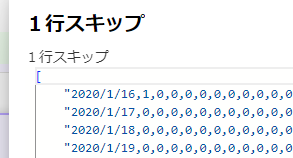
前フローを動かした時には、下の画像のように見出しがありましたので完全に1行をスキップできています
空白行の削除
いよいよ、Sharepointリストに格納!と言いたいところですが、もう一点処理が残っています
もう一度、フローの実行履歴を見てみましょう
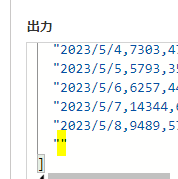
空白行があります
こちらは「アレイのフィルター処理」で削除しておきましょう!
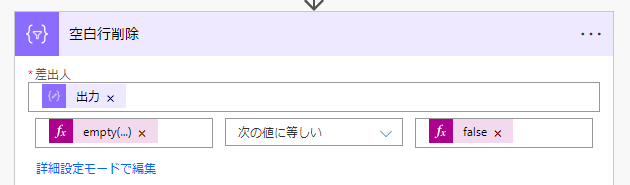
上の画像が空白行を削除するアクションです
差出人の箇所は「1行スキップ」のアクションの結果を動的コンテンツで選択します
そして、以降の処理は「1行スキップ」の結果から1行1行を「ITEM関数」にて抽出してフィルターをするという流れになります
ですので、フィルターの条件式には以下のような式を入れます
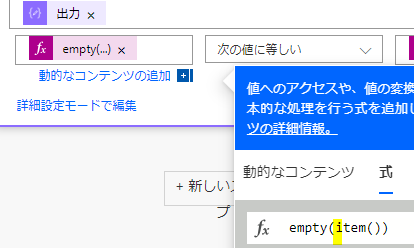
empty(item())
上の分では、empty関数で抽出結果が空白かどうかを判定しています
そして「false」、つまり、空白というのが成り立たないという条件式を作成します
これで空白行をフィルター処理できます
Sharepointリストに格納
これからいよいよSharepointリストにデータを格納します
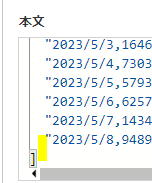
空白行を削除した段階では、データは以下のような形になっています
[ “2020/1/16,1,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ,0,0,0,0,0,0,0,0,0,0,0”, “2020/1/17,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ,0,0,0,0,0,0,0,0,0,0,0”,(省略)
“2023/5/7,14344,658,127,116,293,133,117,188,106,266,175,774,709,2345,886,384,212,214,88,97,278,306,185,863,102,113,267,1098,423,159,52,105,32,122,217,114,66 ,150,105,40,687,87,114,133,121,95,168,254”, “2023/5/8,9489,577,87,68,208,57,107,143,236,113,128,350,372,1331,567,332,111,97,66,202,316,148,260,425,230,42,111,547,408,76,111,47,0,173,434,72,27 ,64,45,23,289,30,27,55,94,47,86,150”]
ですので、1行単位を更に「,」で区切っていく必要があります
これには前述のSPLIT関数とITEM関数を使用する必要があります
つまり以下のような仕組みを作成する必要があります
1.分割
1行データ:①,②,③
⇒
①
②
③
2.割り当て
①⇒1列目、②⇒2列目、③⇒3列目
この仕組みを作成するには、まず、Apply to eachアクションにより空白行を削除したデータを繰り返し抽出できるようにします
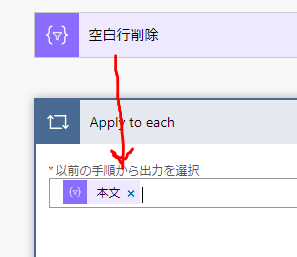
実際にはITEM関数で抽出するのですが、抽出したデータはSPLIT関数にて「,」文字により分割します
split(item(),’,’)
これでデータは
①
②
③
という形になります
更にこの分割したデータを項目の作成アクションで各列に割り当てます
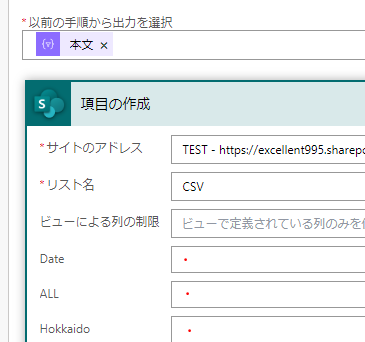
この割り当て処理には?と[]を使用します
split(item(),’,’)?[0] ⇒ split(item(),’,’)?[1] ⇒ split(item(),’,’)?[2]
[]の中に数字を入れて、列の位置を指定する形になりますこれでSharepointリストの各列に分割したデータを割り当てることができます
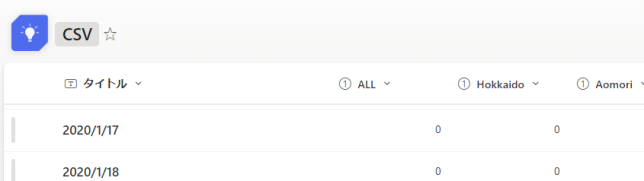
ちなみに、数字は0から始まる点にご注意ください
<まとめ>
今回はCSVファイルを解析してSharepointリストに格納するフローについて解説しました
あくまで今回の内容は基本パターンです
ここから改行コードが別なもののパターン、分割したデータからカンマを更に切り取るパターンなどがでてきます
但し、どのパターンになっても今回の内容があくまで基本となると考えますので、ぜひ参考にして頂きたいと思います
最後に、今回の参考になる過去記事を紹介させて頂きます
参考記事1:難解そうなPOWER AUTOMATEのデータ操作コネクタの概要に触れる







コメントを残す