こちらのコーナーでは、DAX関数*をうまく使うためのコツを解説します
*エクセルのワークシートでは関数に相当するもの
目次
フィルター評価と行評価
フィルター評価
Power BIのレポート画面では常にフィルター評価の影響を受けます
この点は常に意識しておく必要があります
例えば、次のようなデータがあったとします
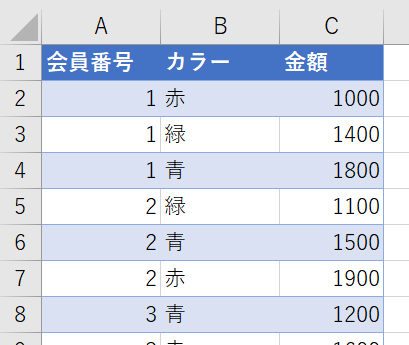
こちらのデータをマトリックスで表示すると次のようになります
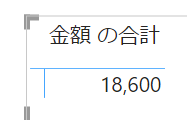
こちらのマトリックスの行にカラーを入れてみます
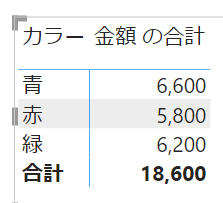
こちらは行単位で青、赤、緑のフィルターが適用されています
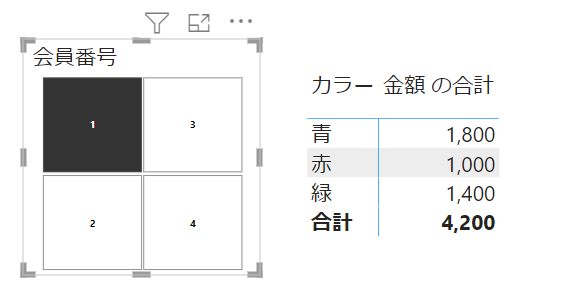
上の画像では、スライサーのフィルターが適用されています
このように、レポート画面ではフィルターの影響を常に受けるわけですが、DAXも同様です
但し、CALCULATEをDAX式で活用するとルールが変わります
試しに、青色の金額を抽出するCALCULATE関数でメジャーを書いてみます
Color_BLUE = CALCULATE(SUM(myTable[金額]),’myTable'[カラー]=”青”)

スライサーのフィルターを解除した上で、上記のメジャーをマトリックスに配置してみます
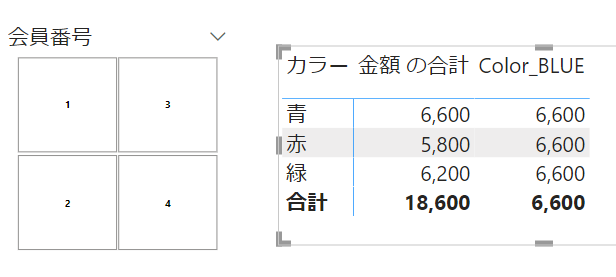
マトリックスの行単位での色別のフィルターは解除され、全て同じ値/6,600になっています
今度は、スライサーのフィルターを適用してみます
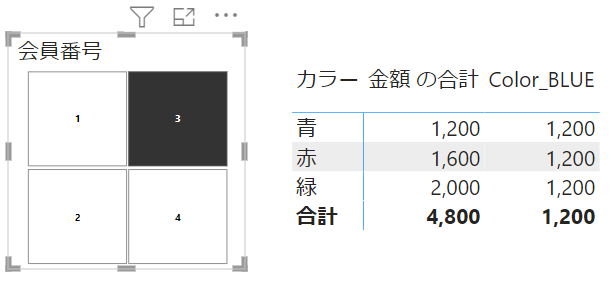
DAX外のフィルターはきちんと適用されているのが分かります
今度はメジャーにKEEPFILTERS関数を適用してみます
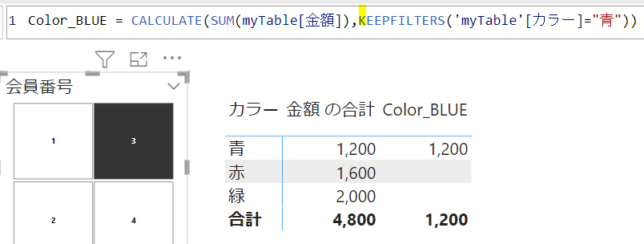
今度は、行単位での色別のフィルターが適用されています
以上、レポート画面では常にフィルターの影響を受ける点とCALCULATE関数を使うとルールが変わる点は常に意識しておきましょう!
行評価
フィルター評価と同じくらい重要で、フィルター評価より難解なのが行評価です
こちらは、明確にフィルター評価と区別して理解しましょう
例えば、次のようなデータがあるとします
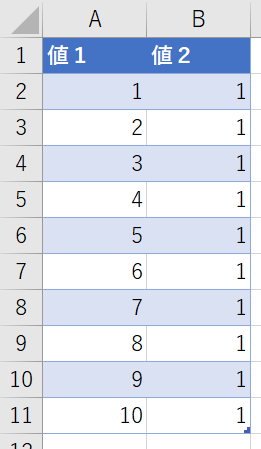
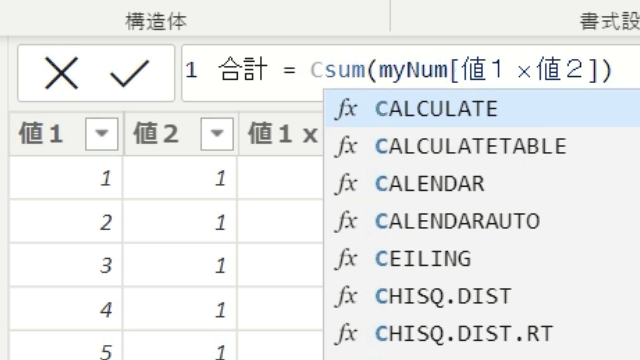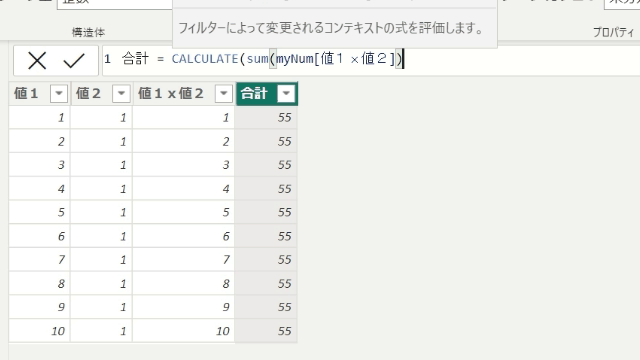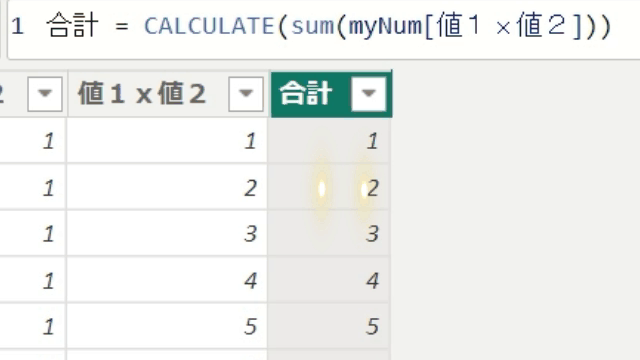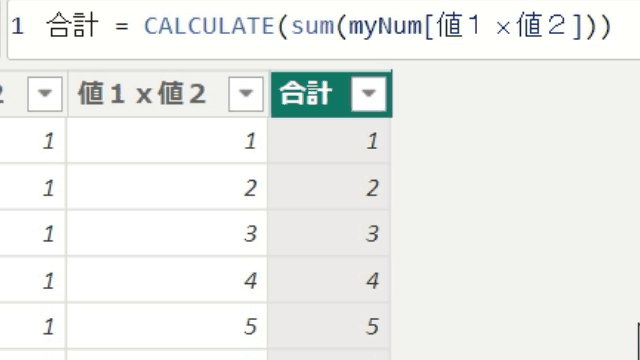
こちらのデータから、行毎に値1と値2を乗算する列を作成してみます
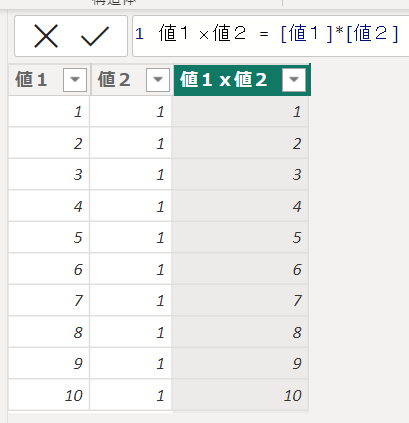
次に値1x値2の列を合計する列を作成します
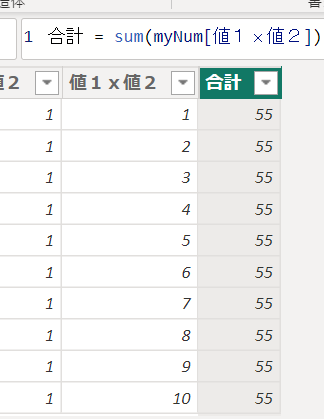
では上の画像と同じ「55」を算出するメジャーを、新しく作成した列をつかわないまま作成するにはどうしたらいいでしょう?
次のように式を書くと、突拍子もない数字になります

これはSUM関数が列自体を計算対象にしているからです
では、ここでSUMX関数を使用してみましょう!
expressionの箇所が「行評価」になっています

SUMX関数を使うと、テーブル「myNum」の1行1行を計算して合計するので正しい数字が出ています
これが行評価となります
行評価では、新しい列の作成と同じように1行1行を対象とするので、フィルター評価とは明確に区別する必要があります
ちなみにCALCULATE関数を使用すると、フィルター評価と同じようにルールが変わります
今回は、隣の列全体を合計するのではなく、1行1行の合計値を算出しています
このCALCULATE関数を使うとルールが変わる点は常に頭に入れておきましょう!
VARとRETURN~中学数学の要領でDAX使用~
DAXはVARとRETURNを使うと更に有効の活用できます
というより、VARとRETURNを使わないとかなりDAXを使う意義が薄れます
VARは変数/VARIABLEの略です
このVARを箱として活用します
エクセルのワークシートでも同じことができます
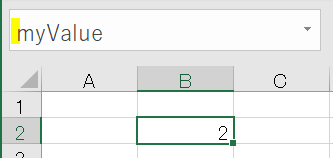
B2セルにmyValueという名前をつけました
この名前がVARに相当します
そしてD2セルで下の画像のようにmyValueを使ってみます
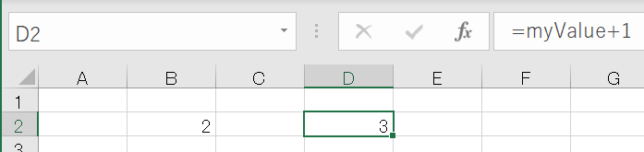
このD2セルの3がRETURNになります
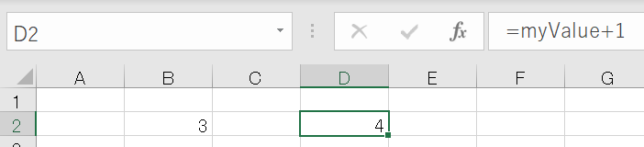
ちなみに、B2セルの値のmyValueを2から3に変えるとD4セルのリターンは4になります
では、上記と同じ内容をPower BI内でも行ってみます
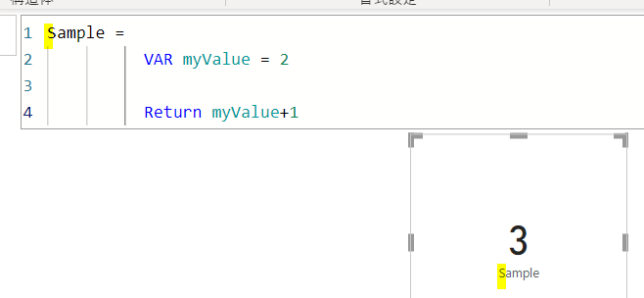
上の画像では、myValueという箱に2を入れ、更に1を加えてリターンしています
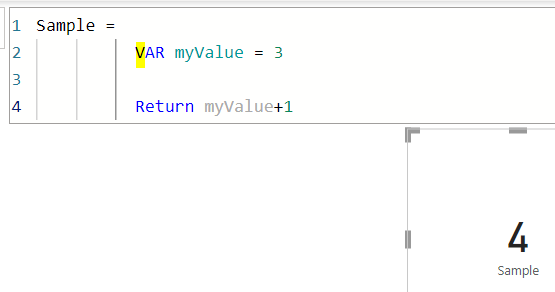
では、myValueを3にすると4がリターンします
実際には、このVARを多数組み合わせて使う形になります
ALLとALLSELECTEDとの使い分け~構成比の罠~
ALLとALLSELECTEDの違いがDAXを使用したばかりだとよくわからないと思います
そもそも、ALLって何のためにあるの?という方も中にはいらっしゃると思います
ALLはスライサーなどでフィルター処理が行われた場合のためにあります

上のGIF画像では、分子がフィルターされた場合にも、分母の全体売上はALL関数により変わらないようになっています
ところが、分母の内容自体がフィルターされる場合が厄介です
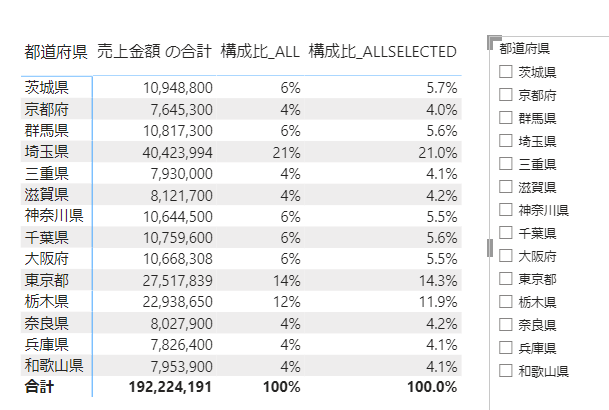
上の画像では、構成比の分母は各都道府県の合計になります
仮に3つの都道府県にフィルターした場合には次のようになります
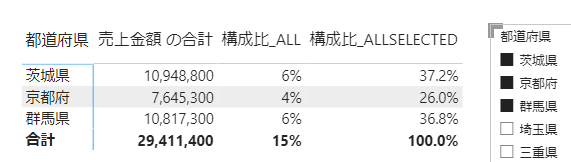
構成比_ALLの場合には、分母が固定ですから、小計が100%を割ります
構成比_ALL = DIVIDE(SUM(‘売上データ3′[売上金額]),CALCULATE(SUM(‘売上データ3′[売上金額]),ALL(‘売上データ3’)))
構成比_ALLSELECTEDの場合には、フィルターと連動して分母が動きます
構成比_ALLSELECTED = DIVIDE(SUM(‘売上データ3′[売上金額]),CALCULATE(SUM(‘売上データ3′[売上金額]),ALLSELECTED(‘売上データ3’)))
つまり、分母が何か?スライサーでフィルターする内容は何か?によってALLとALLSELECTEDを使い分ける必要があります
SUMX関数による高度な集計
エクセルのワークシート関数でもSUM系の関数は多数あります
SUM、SUMIF、SUMIFS、SUMPRODUCT・・・
DAXのSUMX関数は、ワークシート関数のSUMIFS関数とSUMPRODUCT関数を組み合わせた高性能なDAX関数です
次の表を見てください
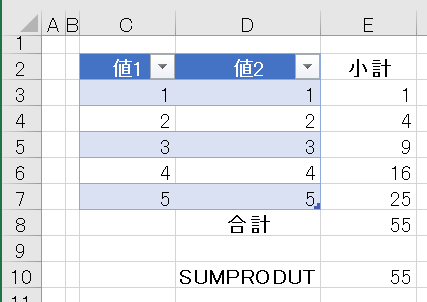
値1の列と値2の列をそれぞれ掛け合わせ、E8セルで合計しています
E10セルにはSUMPRODUCT関数が入っており、列1と列2をそれぞれ乗じつつ、各行の結果を合計しています
H3セルにはSUMIFS関数が入っており、G3セルの条件に応じて、列1と列2を乗じた値の合計を計算しています
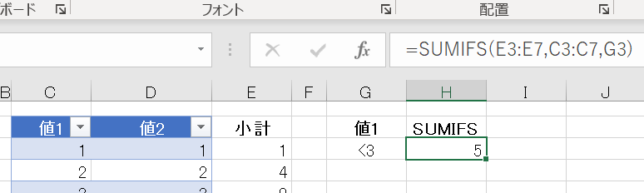
但し、Eの列で算出した値を参照しています
SUMPRODUCT関数のように、単独では計算できません
DAXのSUMX関数では、このSUMPRODUCT関数とSUMIFS関数の組み合わせを一発で計算できます
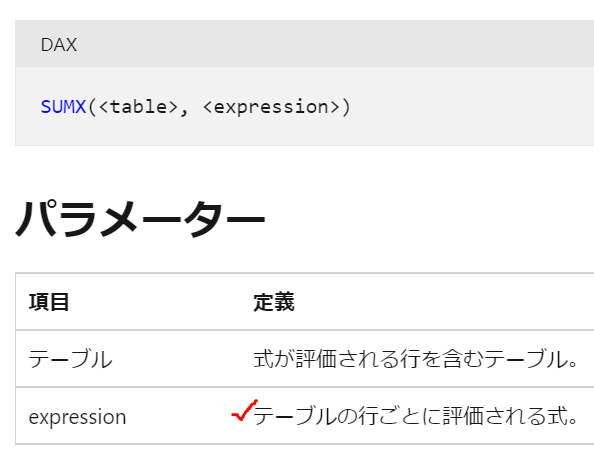
SUMX関数の文法は次のようになります
SUMX(テーブル,式)
試しに、前述のSUMPRODUCT関数と同じことをしてみます
元データは前と同じデータ(テーブル名:myTable)になります
下の画像では、myTableを第一引数のテーブルとして指定し、第二引数で式を指定しています
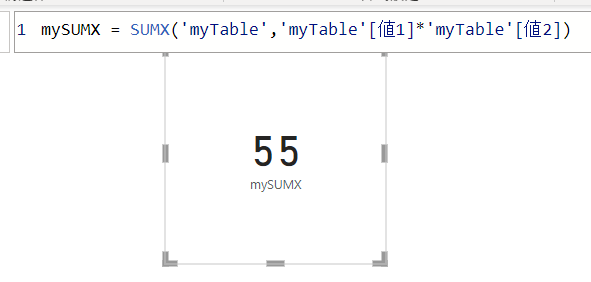
mySUMX = SUMX(‘myTable’,’myTable'[値1]*’myTable'[値2])
今度は、SUMIFS関数と同じように列1の値が<3とします
この場合は、第一引数のテーブルにFILTER関数を使います
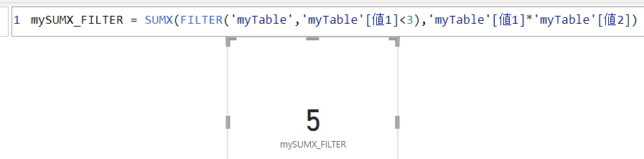
mySUMX_FILTER = SUMX(FILTER(‘myTable’,’myTable'[値1]<3),’myTable'[値1]*’myTable'[値2])
これで、SUMIFS関数とSUMPRODUCT関数との組み合わせを計算できています
嬉しいのはSUMX関数ではSUMPRODUCT関数と違い、式を自由に指定できる点です
DAXの可能性をまさに感じさせる関数だと思います
SUMMRIZE関数による一時テーブルの作成
DAX関数内で参照用の一時テーブルを作成するのにとても便利です
文法は次の通りとなります
SUMMRIZE(テーブル,集計する切り口にする列,新列名1,集計式1,新列名2,集計式2・・・)
早速、使用例を見てみましょう
元のデータは次の通りです
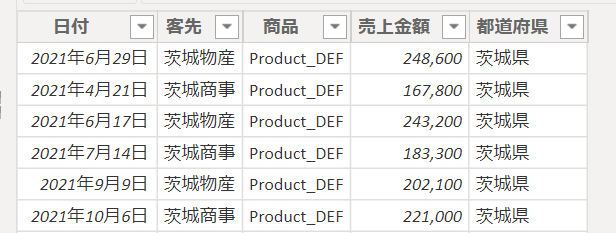
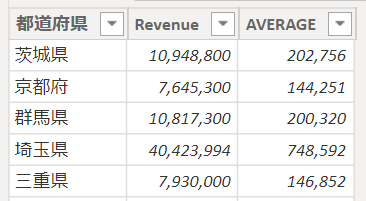
これが上の画像のテーブルから都道府県別の売上合計、平均を算出するSUMMRIZE関数の事例1です
mySummarize = SUMMARIZE(‘売上データ3’,’売上データ3′[都道府県],”Revenue”,SUM(‘売上データ3′[売上金額]),”AVERAGE”,AVERAGE(‘売上データ3′[売上金額]))
事例2として集計の切り口を都道府県のみから、商品も加えてみましょう
mySummarize+Product = SUMMARIZE(‘売上データ3’,’売上データ3′[都道府県],’売上データ3′[商品],”Revenue”,SUM(‘売上データ3′[売上金額]),”AVERAGE”,AVERAGE(‘売上データ3′[売上金額]))
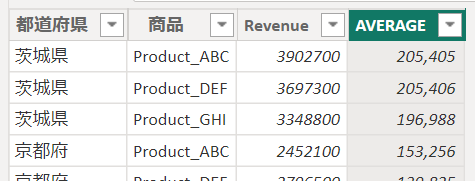
ピボットテーブルと同じような形ですよね
HASONEVALUE~値が複数か否か~
こちらのDAXは、値が複数あるケースとそうでないケースで表示を分けるのに便利です
値が複数ある場合は、FALSE、そうでない場合はTRUEを返します
ただ、上記の説明だと使用シーンが明確に浮かばないとおもうので実際の例を見てみましょう

上の画像にあるようなメジャーを作り、カレンダーテーブルの内容を行に仕込んだマトリックスの中にいれてみます
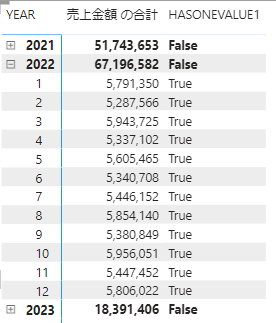
すると、MONTHの箇所は一つしか値がないのでTRUEになり、YEARの箇所はMONTHが複数あるのでFALSEになります
次にもう一つメジャーを作成します

IF式を使い、HASONEVALUEがTRUEであれば、金額を表示するようにします
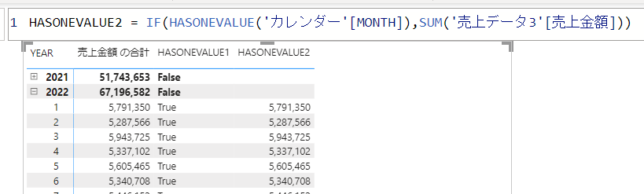
YEARとMONTHで表示を切り替えられるようになりました
ISBLANKとISEMPTY~空白?空欄~
ISBLANKとISEMPTY、似てるようで明確に違いがあります
具体的には何が違うのでしょう?
ISBLANKは対象が列、ISEMPTYはテーブルが対象になります
ISBLANK
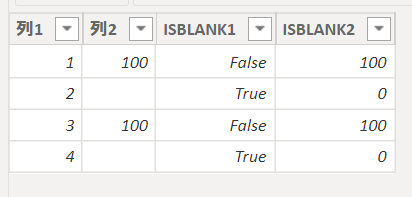
下の画像では「ISBLANK1」という新しい列を追加しています
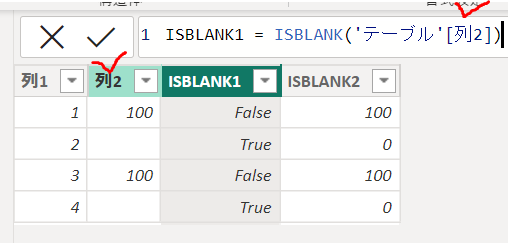
空欄の行では「TRUE」を返しています
次の画像ではIF式と組み合わせて空欄を0に置き換えています
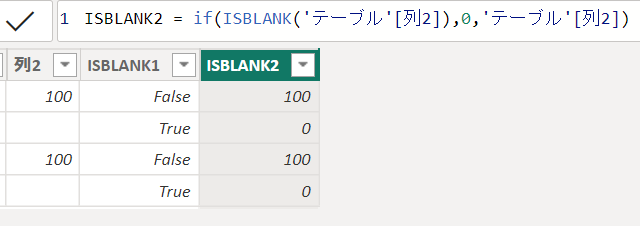
ISEMPTY
ISEMPTY関数を使い、次のようなメジャーを作成してみます
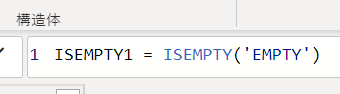
上の画像内の「’EMPTY’」は次の画像のテーブルです
このメジャーの内容をカードで出力してみます
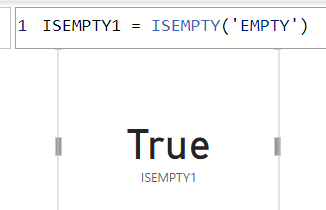
こちらはTrueで出力されます
今度はISEMPTYの中身のテーブルを変えてみます

’テーブル’は空でないのでFalseが返されます
REMOVEFILTERS関数~フィルターの影響を避ける~
思わぬところでフィルターの落とし穴にはまったことはないですか?
以下のグラフでは折れ線グラフが100%のまま水平になっています
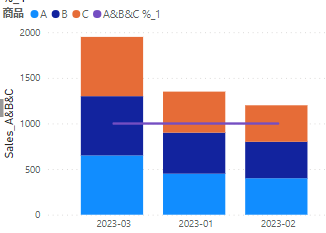
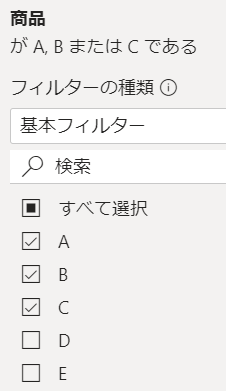
これは元のデータにはABCだけでなく、EやFもあるのです
ただ、フィルターがかかっています
このフィルターがかかっている状態にて、折れ線グラフで使用するメジャーは次のような数式になっているのです

分子のメジャーは商品ABCの合計です
分母は全体の合計です
ただ前述のようにフィルターはABCにかかっています
ですので分母は常に商品ABCです
だから100%のままです
この場合にREMOVEFILTERS関数を使用します

A&B&C %_2 = DIVIDE(‘DATA'[Sales_A&B&C],CALCULATE(SUM(DATA[値]),REMOVEFILTERS(‘DATA'[商品])))
このREMOVEFILTERS関数により、商品に対してかかっているフィルターを取り除きます
そうすることで分母を常に正しく計算することができます
ちなみにALL関数を使うと時系列でのフィルターがかからないため、分母が異常に大きくなってしまいます
SUMMARIZECOLUMNS関数~簡単にグループ化~
SUMMARIZECOLUMNS関数を使用すると、下のようなデータを簡単にグループ化することができます
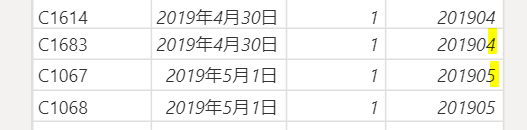
新しいテーブルからこのDAX関数を使用してみます

yyyyMM列をグループ化の切り口として「月小計」という列を作成し、「月小計」に受注数のグループ別の小計を計算します

NewTable=SUMMARIZECOLUMNS(①’OrderData'[yyyyMM],②”月小計”,③SUM(‘OrderData'[受注数]))
たった3つの引数だけで作成できるのでとても便利です
①:グループ化の切り口、②新列名、③計算式
こちらの関数は次のように変数にSUMMARIZECOLUNS関数で作成したテーブルを代入して使用することもできます
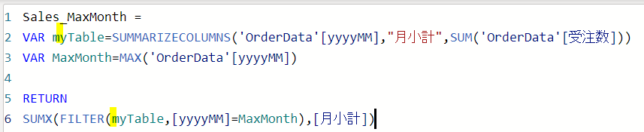
Sales_MaxMonth = VAR myTable=SUMMARIZECOLUMNS(‘OrderData'[yyyyMM],”月小計”,SUM(‘OrderData'[受注数]))
VAR MaxMonth=MAX(‘OrderData'[yyyyMM])
RETURNSUMX(FILTER(myTable,[yyyyMM]=MaxMonth),[月小計])
CALCULATE関数にて複数条件を指定する
CALCULATE関数は条件を指定しながら様々な集計ができる便利なDAX関数です
複数条件を指定する場合には次のような式になります
AND条件
CALCULATE関数に条件を追加する場合には「コンマ」を追加します
例えば、下の画像のデータから(商品=A)and (月=202303)という条件で合計金額を集計したいとします
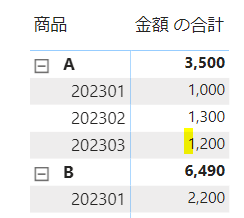
その場合のメジャーは次のようになります
商品:A and 月:202303 = CALCULATE(SUM(‘DAX1′[金額]),’DAX1′[商品]=”A”,’DAX1′[月]=202303)
OR条件
OR条件の場合には「||」を使用します
商品:A or 商品:B = CALCULATE(SUM(‘DAX1′[金額]),’DAX1′[商品]=”A” || ‘DAX1′[商品]=”B”)
この場合、「in」を使用するという方法も使えます
商品:A or 商品:B_in使用 = CALCULATE(SUM(‘DAX1′[金額]),’DAX1′[商品] in {“A”,”B”})
SWITCH関数とTRUEの組み合わせ
通常
SWITCH関数は場合分けをするケースでとても便利です

注文金額3 = SWITCH(‘分析用2′[注文金額],1200,”1200″,8600,”8600″,”X”)
IF関数と比べて条件を複数追加することができます
ただ条件設定が「=しか指定できない」、「指定順序が間違いやすい」などの問題があります
TRUE
SWITCH関数の第一引数を「TRUE」とすると、もっと柔軟に条件を指定できるようになります
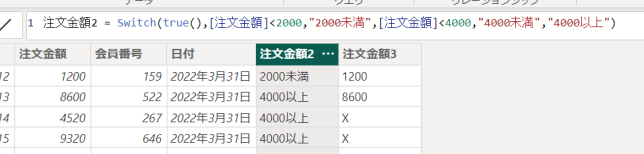
注文金額2 = Switch(true(),[注文金額]<2000,”2000未満”,[注文金額]<4000,”4000未満”,”4000以上”)
RANKX関数~順位付け~
DAXのRANKX関数を使えば、集計した値に対して順位付けが行えますのでとても便利です
RANKX関数の文法自体はとても簡単なものですが、実際には少々トリッキーな面があります
文法:RANKX(使用テーブル,順位を判断する値)
*実際には他にも指定できます
作成してみたけど結果が全て1になってしまった、という方も中にはいらっしゃると思いますので、トリッキーな面を中心に解説を行います
解説に使用するテーブル/テーブル名:Tableは以下です。カテゴリーが大小2つあります
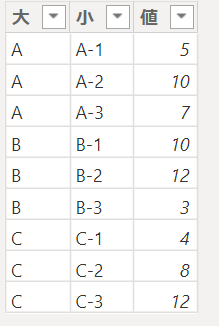
こちらのデータから大、小のカテゴリーにて順位付けを行えるようにします
判断に使用する値は予めメジャーで算出しておきます
これが1つ目の大きなポイントです

次に実際にカテゴリー大を順位付けするメジャーを作成します

ここでAllを使用するのが2つ目の大きなポイントです
そして、Allの引数はカテゴリー列も指定します
Allを使用しないと、ビジュアルで表示する時にフィルターが効いて全て1になります
他の言葉で言い換えると、フィルターが効いても他の行の値と比較して順位付けできるようにします
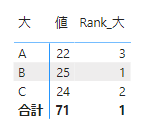
では次にカテゴリー小を順位付けするメジャーを作成します

このメジャーをマトリックス表にセットしてみます
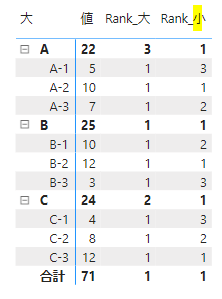
こちらは大カテゴリー内での順位が出力されます
今度は、カテゴリー大の関連はマトリックス表から抜いてみます
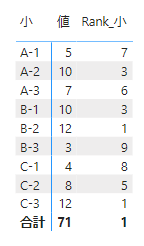
これでカテゴリー小の間で順位付けが行えました
繰り返しになりますが、順位付けを行う値は事前にメジャーにしておきましょう!
DISTINCTCOUNTROWS vs DISTINCT vs VALUES
一見、同じに見えるこれらの関数ですが、何が違うのでしょうか?
試しに、これらの3つのDAX関数を使用して下の画像のテーブルにて「客先名」をカウントするメジャーを作成してみたいと思います
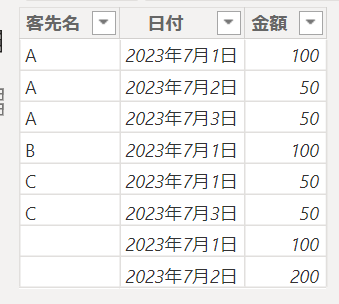
実際に作成するメジャーの中身は次の通りとなります
ちなみにDISTINCT関数とVALUES関数はCOUNTROWS関数と組み合わせます
CountBY DistinctCount = DISTINCTCOUNT(‘売上テーブル'[客先名])
CountBY Distinct = COUNTROWS(DISTINCT(‘売上テーブル'[客先名]))
CountBY Values = COUNTROWS(VALUES(‘売上テーブル'[客先名]))
結果は全く同じ結果になります(空欄もカウントしています)

ではどのような時に結果が違ってくるのでしょうか?
今度は客先マスタで客先名をカウントしてみます
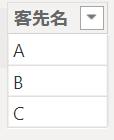
但し、先ほどの売上テーブルとリレーションを組んでおきます
実際に作成するメジャーは次の通りとなります
CountBY DistinctCount = DISTINCTCOUNT(‘客先マスタ'[客先名])
CountBY Distinct = COUNTROWS(DISTINCT(‘客先マスタ'[客先名]))
CountBY Values = COUNTROWS(VALUES(‘客先マスタ'[客先名]))
結果は次の通りとなります

VALUES関数だけ売上テーブルの空欄をカウントしているという結果になりました
CalculateTable関数~テーブルの作成~
テーブルを作成する際に便利なのが、CalculateTable関数です
CalculateTable関数は条件付で計算をするのに便利なCalculate関数のテーブル版です
文法も一緒で、出力されるのがテーブルというだけです
テーブル関数も幾つかありますが、CalculateTable関数を使うケースは次のようなケースが典型的です
Customer IDs = CALCULATETABLE(VALUES(OrderData1[Customer ID]),OrderData1[yyyy-MM]=”2019-07″)
上のDAX式ではVALUES関数と組み合わせて、注文データ/OrderData1から2019年7月に注文があった会員の番号をリスト化しています
こんな風に1列をリスト化するVALUES関数と組み合わせて、条件に合うリストを作るケースなどで便利です
更には「VAR~RETURN」と組み合わせて、CalculateTable関数で出力したリストから更に別なものを出力するといった事もできます
EOMONTH関数~時系列で日付を整理する~
時系列で日付を整理するのに便利なのが、EOMONTH関数です
例えば前月末日を知りたいとします
その場合は次のようにメジャーを書きます

これだけで自動的に前月末日が出力されます
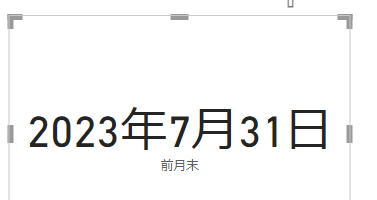
では、前月開始日を出したい場合にはどうしたらいいでしょうか?
その場合は「+1」をうまく使います

これで、開始日も自由に抽出できます

フィルターが複数あるケースで割合を計算する~Calculate&AllSelected&removeFilters~
よくこんな風にフィルターがスライサーを含めて複数かかるケースがあります
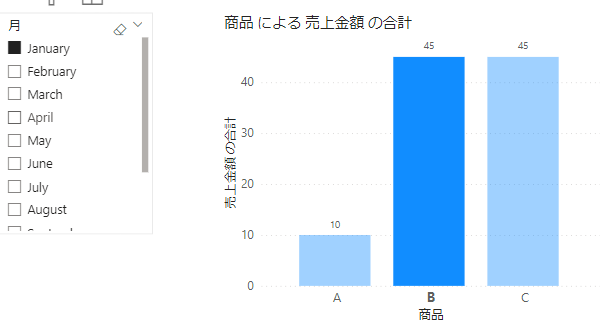
上の画像のケースでは「日付、しかも月」「商品」の2つです
この場合、グラフ内の選択商品の割合をどうやって計算しますか?
下の画像の場合は商品A~Cの合計が100で、選択された商品Bは45なので45%です
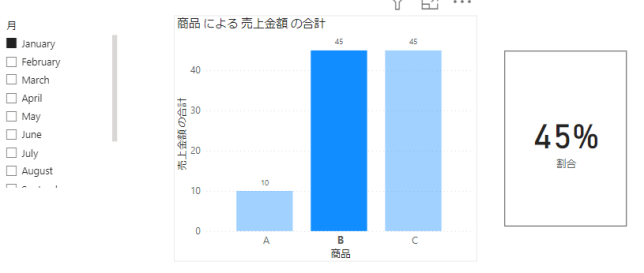
分子は該当の「月」で該当の「商品」の売上金額です
つまり純粋に選択されたものです
ですので以下のメジャーで簡単に算出されます
CALCULATE(SUM(‘テーブル'[売上金額]),ALLSELECTED(‘テーブル’))
では、分母はどうでしょう?意外と難しく感じられませんでしょうか?
フィルターは「月」だけです
ですが、Calculate関数内で指定できるのは「日付単位」です
この場合は、Calculate関数内で次のようにRemoveFilters関数を組み合わせればあっさりと解決します
CALCULATE(sum(‘テーブル'[売上金額]),ALLSELECTED(‘テーブル’),REMOVEFILTERS(‘テーブル'[商品]))
こちらが割合を計算するメジャーです
割合 =
VAR bunshi=CALCULATE(SUM(‘テーブル'[売上金額]),ALLSELECTED(‘テーブル’))
VAR bunbo=CALCULATE(
sum(‘テーブル'[売上金額]),
ALLSELECTED(‘テーブル’),
REMOVEFILTERS(‘テーブル'[商品])
)
RETURN DIVIDE(bunshi,bunbo)
![]()
![]()




参考にさせていただいています。
1つ質問ですが、「SUMMARIZECOLUMNS関数~簡単にグループ化~」の以下のDAXで中間テーブル「myTable」の列「”月小計”」を次の式のSUMX関数の引数で使用されていますが、これは可能でしょうか?
Sales_MaxMonth = VAR myTable=SUMMARIZECOLUMNS(‘OrderData'[yyyyMM],”月小計”,SUM(‘OrderData'[受注数]))
VAR MaxMonth=MAX(‘OrderData'[yyyyMM])
RETURNSUMX(FILTER(myTable,[yyyyMM]=MaxMonth),[月小計])
中間テーブルで作成した列に対してフィルターなどをかけたいのですが、列指定ができなくて何かいい方法がないかと困っています…
よろしくお願いします。
ご連絡ありがとうございます
SUMXなどの関数にFILTERを入れる方法ではいかがでしょうか?
VAR myTable=SUMMARIZECOLUMNS(‘OrderData'[yyyyMM],”月小計”,SUMX(FILTER(‘OrderData’,’OrderData'[受注数]>1),OrderData[受注数]))
ご返信お待ちしております
早速のご連絡ありがとうございます!
普通はそちらでよいと思うのですが、実は返品があるデータに対して、またスライサーで指定した期間に対して数量をSUMをして、それに対して「0より多い」にしたいと思っています。
なので、まずはスライサーで指定した期間に対して中間テーブルで例えば顧客コードごとに数量をSUMして、その中間テーブルで「SUMした数量」に対して「0より多い」をしたいのですが、中間テーブルの「SUMした数量」列を指定できないと思ってまして…。
別のサイトで同じ質問をさせていただいたのですが、誰も返答がなくて、もしお知恵をお借りできれば大変助かります。
〇質問内容
以下のとおりファクトテーブルとして「Sales」、ディメンジョンとして「Customer」があるとします。
【Sales】
販売日 顧客コード 数量
2021年7月20日 10 1
2021年8月10日 20 1
2021年10月2日 30 3
2022年6月20日 40 1
2022年6月20日 50 1
2022年7月1日 10 2
2022年7月2日 20 3
2022年7月3日 30 1
2022年7月4日 50 1
2022年7月5日 20 1
2022年8月1日 10 -2
【Customer】
顧客コード 担当者
10 Aさん
20 Aさん
30 Bさん
40 Bさん
50 Bさん
また、スライサーとして販売日を期間で指定した場合、その期間に応じて以下のような配荷数、および未配荷リストを算出したいです。
配荷数は指定した販売日の期間の中で売上があった顧客の数です。(ただし、その期間内の合計数量がプラスであること)
上記テーブルで例えば「スライサー:2022年1月1日~2022年12月31日」とした場合、
担当者 配荷数
Aさん 1
Bさん 3
※Aさんの配荷数は「2022/7/1」と「2022/8/1」の数量がそれぞれ「2」と「-2」で相殺されるため、
顧客コード「10」はカウントしない
未配荷リスト
10
返品が無ければ配荷数を算出できるのですが、返品が邪魔してて…
突然質問してしまい申し訳ございません。
よろしくお願いしますm(__)m
大変申し訳ないですが、やりたいことが明確にわからないので全部を答えるのは困難かと思います。完成予定の表とかを例示されるといいかと思います。
やりたいことの一つはSUMMARIZECOLUMNS関数を使用することでしょうか?スライサーで期間指定するということは、SUMMARIZECOLUMNS関数での集約の切り口が「日付」と「顧客」になりますでしょうか?
日付を入れないと期間指定ができないです。別テーブルとリレーションしても日付データがないことには期間指定ができません。逆に日付で集約するとSUMMARIZECOLUMNS関数にて、顧客の切り口での集約ができません。
ですので、SUMMARIZECOLUMNS関数を使用することではないとは思いますがいかがでしょうか?
こちらこそ説明不足など大変申し訳ございません。
実施したいことは「配荷数」の算出で、弊社の各セールスマンが担当している顧客にまんべんなく営業して実績をのこしているか?仲の良い顧客ばかり営業していないか?を調べるためになります。
こちらでファイルを添付できれば良いのですが、できないのでテキストでサンプルとしてテーブルを挙げさせていただきますが、以下のとおりファクトテーブルとして「Sales」、ディメンジョンとして「Customer」があるとします。
もちろんカレンダーテーブルもあるとします。
「Sales」と「Customer」は「顧客コード」でリレーションされています。
また、「Sales」と「カレンダー」は「販売日」でリレーションしています。
【Sales】
販売日 顧客コード 数量
2021年7月20日 10 1
2021年8月10日 20 1
2021年10月2日 30 3
2022年6月20日 40 1
2022年6月20日 50 1
2022年7月1日 10 2
2022年7月2日 20 3
2022年7月3日 30 1
2022年7月4日 50 1
2022年7月5日 20 1
2022年8月1日 10 -2
【Customer】
顧客コード 担当者
10 Aさん
20 Aさん
30 Bさん
40 Bさん
50 Bさん
ビジュアルとしてはスライサーで「販売日」を期間で設定しています。(実際にはカレンダーテーブルの日付をセットすると思います)
それらを踏まえて、例えば「スライサー:2022年1月1日~2022年12月31日」とした場合、算出したいものは以下の
ものになります。
【各担当者別配荷数】
担当者 配荷数
Aさん 1
Bさん 3
【未配荷リスト】
担当者 顧客コード
Aさん 10
ということをしたいと思って、DAXを試してたり、ネットで調べたりしているうちにこちらのサイトにたどり着きました。
期間をスライサーで動的にしても、返品データが無ければ簡単なのですが、返品があることにより流れとしては、指定した期間に対してまずは顧客コードごとに数量をSUMする必要があります。その上で顧客コードごとにSUMした数量が0より多い顧客コードに対してCOUNTROWする流れではないかなぁと思っていますが、その中間テーブルを作成するためにSUMMARIZECOLUMNS関数やSUMMARIZE関数を試してました。しかし、そのテーブルの列を続きのコードで指定できないので、SUMした数量を0より多いという条件を追加できないと思っていました。
ところが、SUMMARIZECOLUMNS関数の「月小計」列を続きのコードで指定されていたので、あれっ、指定できるのかな?と思って質問させていただいた次第です。
大変長文になり申し訳ございません。
よろしくお願いいたします。
返信ありがとうございます
お話の印象としては、メジャー(販売個数-返品)だけ作成して、後はビジュアルで工夫した方が早い気がしました
(レポートビューのフィルターを使用するなど)
あまりお役に立てなくてもうしわけありません