

【知らなきゃ損!Power Appsに簡単にPDFを作成するツールがあります】 「PCで表示されている内容をそのままPDFにできたらいいのに・・・」と思ったことはないでしょうか? Power AppsのPDF関数をうまく…

【VBAができるのなら、PDFのエクセル変換はPower Automate Desktopを活用しよう!】 企業向けの仕事をしていると「PDFからの転記」処理に苦しんでいるシーンをよく見ます もちろん世の中には自動変換ソ…

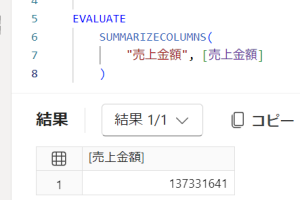
【エクセルでシート別にわざわざ表を作成しなくても、簡単に表は作成できるんです!】 先日、PDFでデータを送付するため、わざわざエクセルのシート別にデータを管理している事例をみました 確かに、エクセルだと罫線が入った表をき…
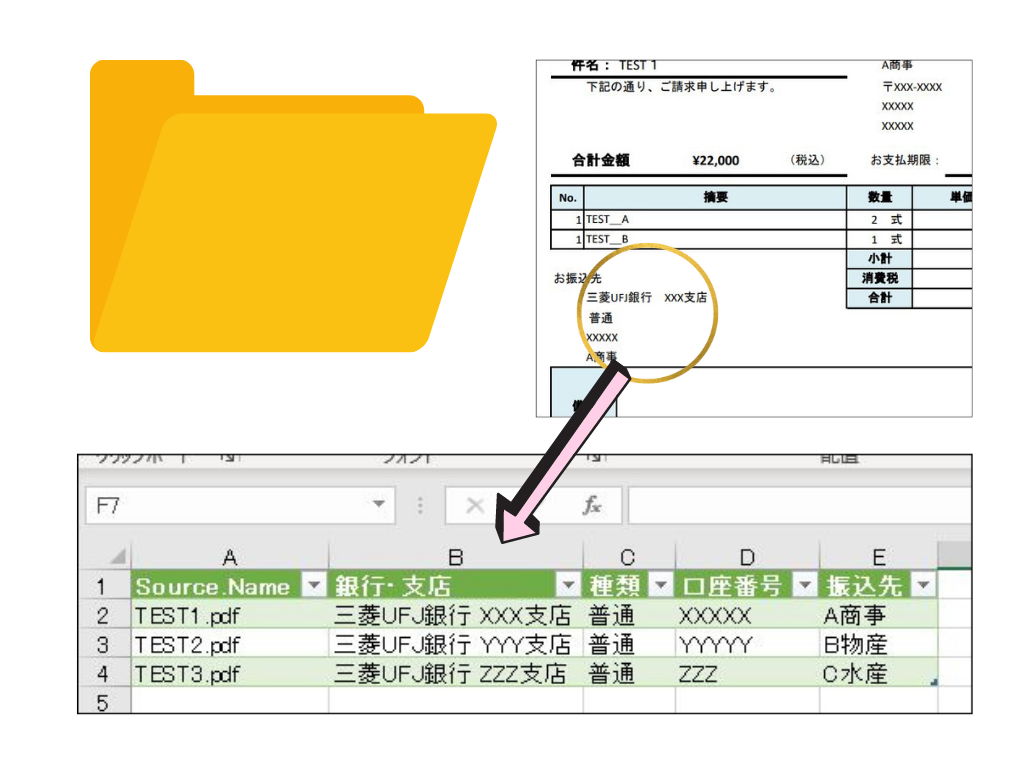
今回はフォルダに入れた複数PDFファイルから、一部の箇所だけデータを一括で取得します 扱うPDFファイルには、以下の画像のように振込先のデータが含まれています このPDFファイルから振込先のデータだけを取得します しかも…
Microsoft社の無料RPA・Power Automate Desktopのアクションの中から、PDF操作のアクションを紹介します ➡逆引き辞典に戻る PDFファイルから1ページの抽出 アクション名:…
RPAには底知れない「便利機能」があります 今回はエクセルVBAで作成したらかなり複雑になりそうな作業を、RPAの画面内で数回のクリックで行えるようにする方法を解説します 具体的にRPAで行う作業は次の内容です ・フォ…
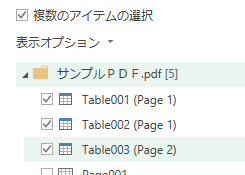
こんにちは、Excellent仕事術のガッツ鶴岡です この記事は、Power Queryというエクセルのスゴイ新機能をまだ知らない人向けに書いている記事です 「エクセルで大量のデータを扱っているけど、何とか作業を効率化し…

ガッツ鶴岡/Gutsy Tsuruoka
┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘
プロから教わるビジネス講座・ウェブ講座が1,000円から!
初心者歓迎、1回から気軽に学べる日本最大級のまなびのマーケット「ストアカ」に今すぐ登録!!
https://px.a8.net/svt/ejp?a8mat=3BSKJM+28YZTM+352U+6BMG3
┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘┘
![]()

最近のコメント