今回はフォルダに入れた複数PDFファイルから、一部の箇所だけデータを一括で取得します
扱うPDFファイルには、以下の画像のように振込先のデータが含まれています
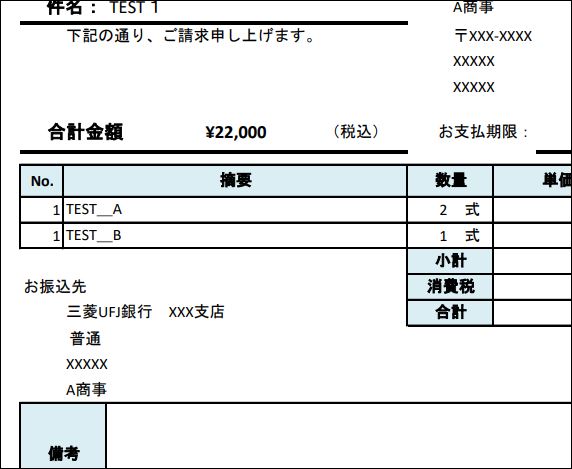
このPDFファイルから振込先のデータだけを取得します
しかもPDFファイルは複数あり、行数が可変になっています
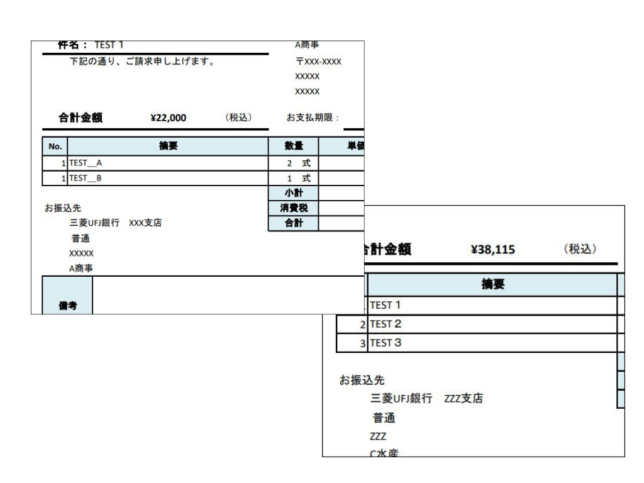
この処理のポイントは大きく分けて2つあります
目次
ポイント
サンプルファイルの変換
今回の処理で主に作業するのは「サンプルファイルの変換クエリ」になります
複数ファイルの1つを変換するクエリを修正して、複数ファイル全てに変換ルールを適用します
M関数の組み合わせ
過去の記事で、見出し位置が不規則な複数ファイルからデータを取得する方法を解説しました
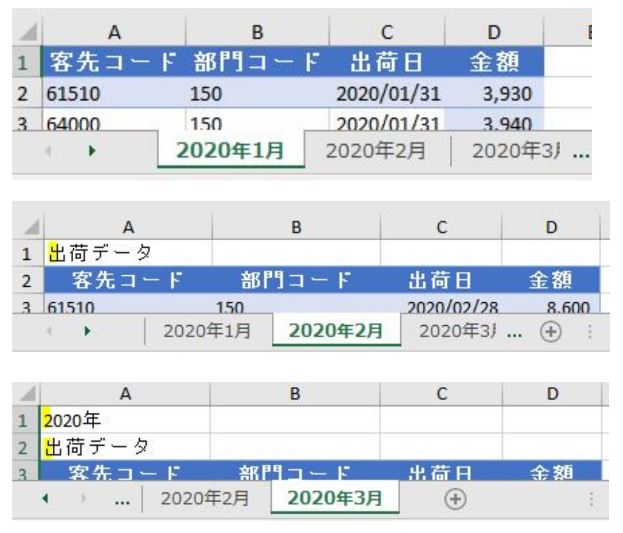
この際、上の画像の見出しをキーにしてList.PositionOf関数とTable.RemoveFirstN関数の組み合わせ「見出しの上の行」を削除しました
今回も同じようにList.PositionOf関数とTable.RemoveFirstN関数の組み合わせを使用します
・List.PositionOf関数 ➡ 指定文字列のList内の位置を取得
・Table.RemoveFirstN関数 ➡ テーブルから指定行の上の行を削除
フォルダから一括取得
まずは複数PDFファイルが格納されたフォルダからデータを一括取得します
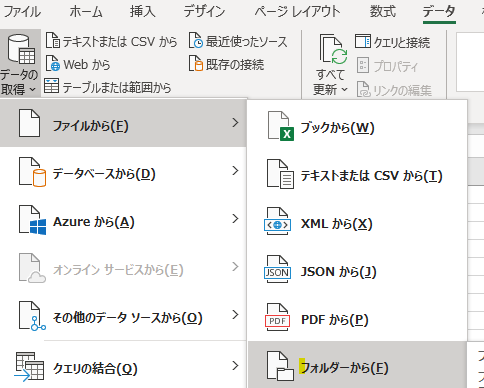
「Fileの結合」画面ではテーブルではなく全ページを指定します
キーの設定
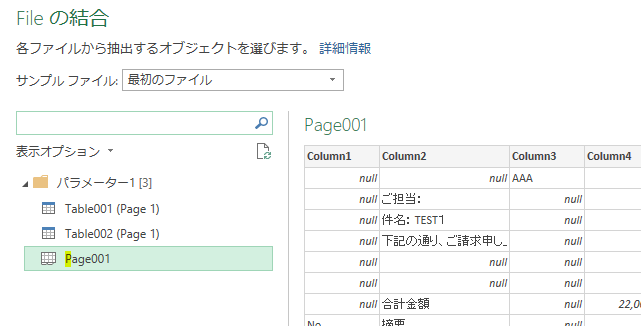
エディタで「サンプルファイルの変換クエリ」を開くと次の画像のようになっています
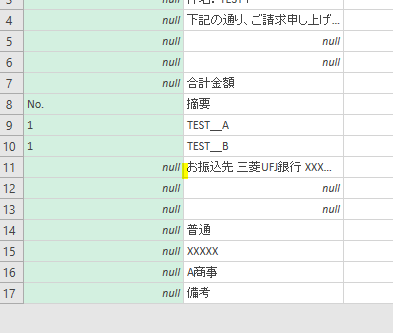
上の画像の黄色く印をした箇所の「お振込先・・・」以降の行から「備考」の上の行までが今回の取得対象です
「お振込先」の文字列をキーに設定した上で以降の作業を進めます
キーの抽出
キーとなる文字列「お振込先」の4文字を、列の追加タブ内の「抽出」メニューを使用して切り取ります

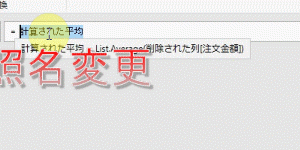
すると下の画像のように「お振込先」の文字列が抽出した列ができます
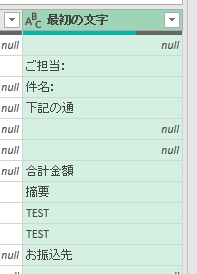
この「お振込先」の文字列より上の行を次から削除します
その前にステップ名は分かり易く変更しておきましょう➡Data2
キーの上の行の削除
ここからM関数を使用します
まずカスタム列作成画面にて、List.PositionOf関数を入力して「お振込先」の文字列がある行を特定します
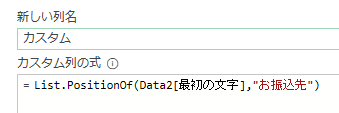
すると10という数字が入った列ができます
「お振込先」の文字列は11行目ですが、M言語は0からはじまるので正しく設定できています
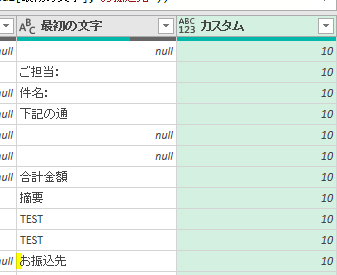
ここからTable.RemoveFirstN関数で上の行を削除します(-1などの調整は必要ありません)
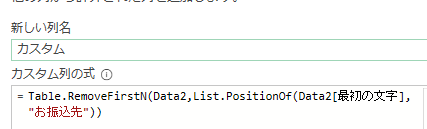
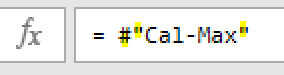
上の画像の数式を文字列にすると次の通りとなります
Table.RemoveFirstN(Data2,List.PositionOf(Data2[最初の文字],”お振込先”))
この数式を作る際には、ステップ名をテーブル名に使用するのもポイントとなります
下の画像が新たに作成されたテーブルになります
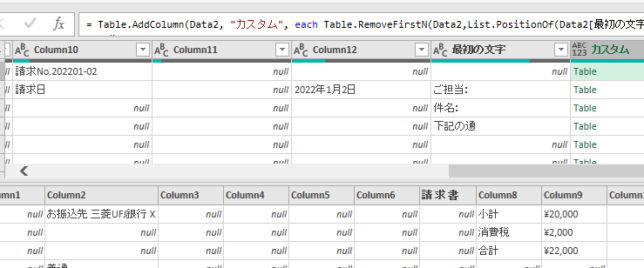
テーブルが複数ありますが、必要なのは一つだけですので「行の保持」で余分なテーブルは削除します
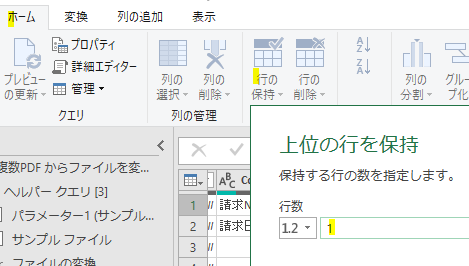
テーブル展開
ここから作成したテーブルの展開処理を行います
まずはテーブル以外の列を削除します
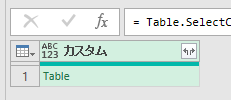
この後、必要な列だけ展開します
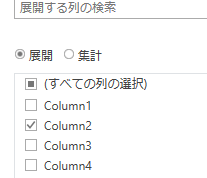
この時点で大分、形になってきました
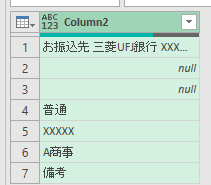
なお、この時点で最終アウトプットを行うクエリでエラーが発生しています
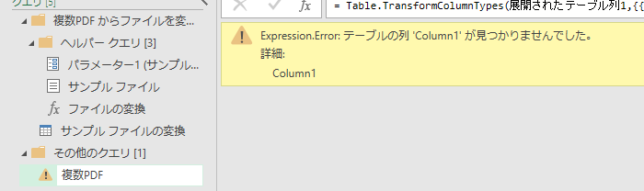
これはサンプルファイルの変換クエリで元ある列を削除しているからです
このエラーは各列の型式を変更する最終ステップを削除すれば消えます
では、変換クエリに戻ります
ここからは最終調整です
最終調整
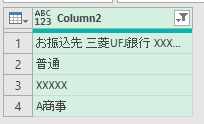
上の画像のように、空欄や「備考」などの文字をフィルターで取り除きます
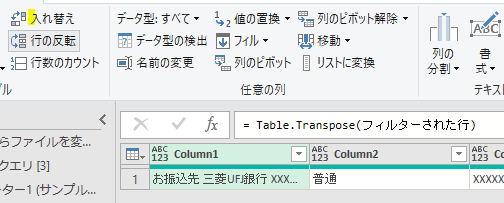
この状態から行列を入れ替えます
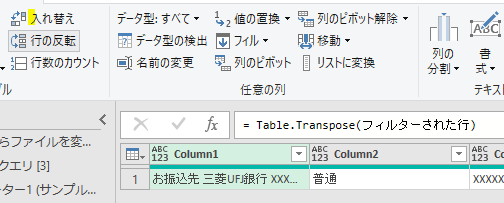
ここからは列名を整えるのですが、お振込先の文字は「列の分割」メニューで切り取っておきましょう

では、最終アウトプットのクエリを見てみましょう

うまくデータが複数作成できています
<まとめ>
今回は複数PDFファイルのデータから、キーのデータより上にある行を削除して必要な箇所だけ抽出しました
M関数のList.PositionOf関数とTable.RemoveFirstN関数をうまく組み合わせれば、意外と簡単に行えます
今回は、抽出データの下にあるデータはフィルタしただけで済みましたが、実際には複雑なパターンもあるかもしれません
その際は過去記事で紹介した「インデックス列と余り、減算の算出」の組み合わせが有効かもしれません
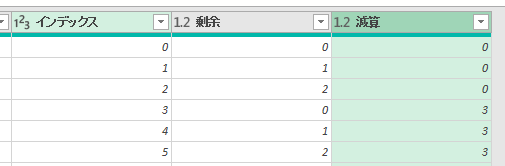
あわせて覚えておいていただけると幸いです
![]()
![]()







コメントを残す