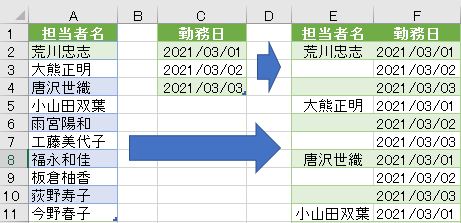
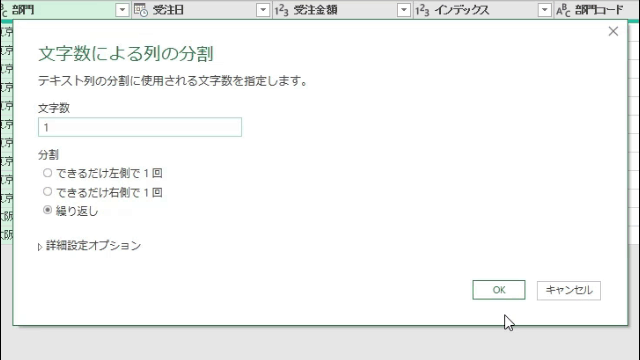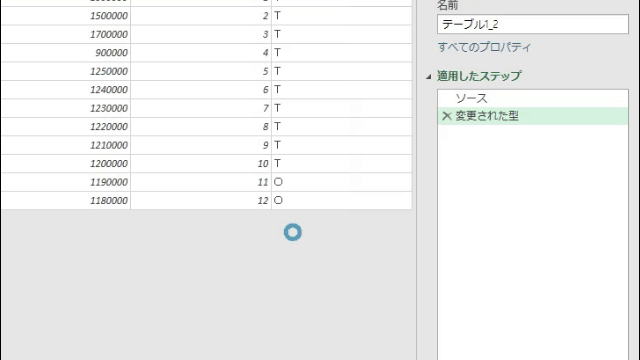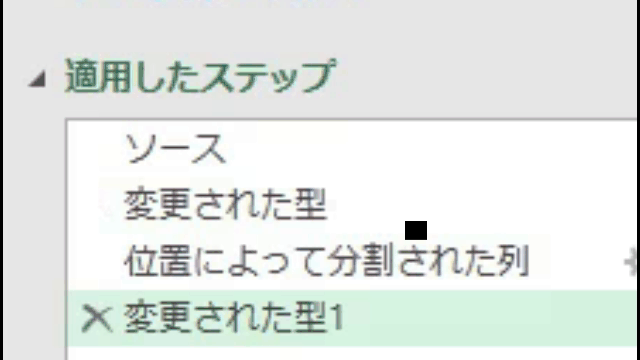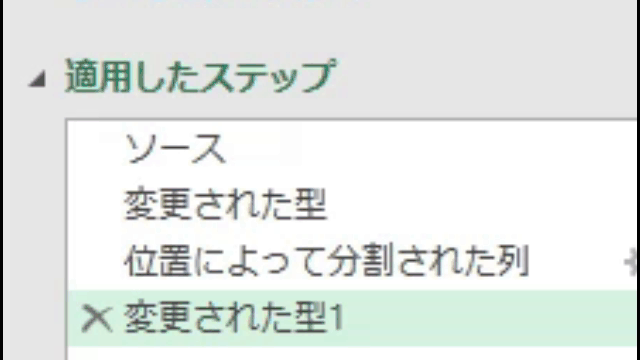
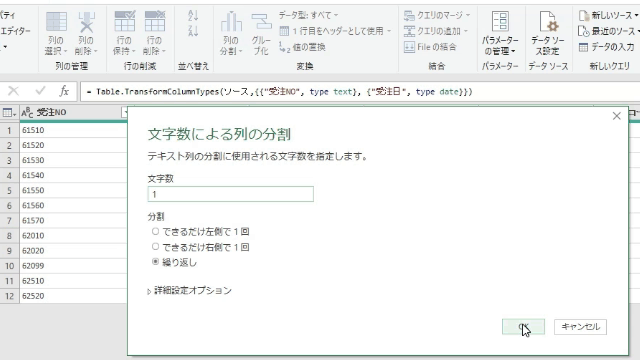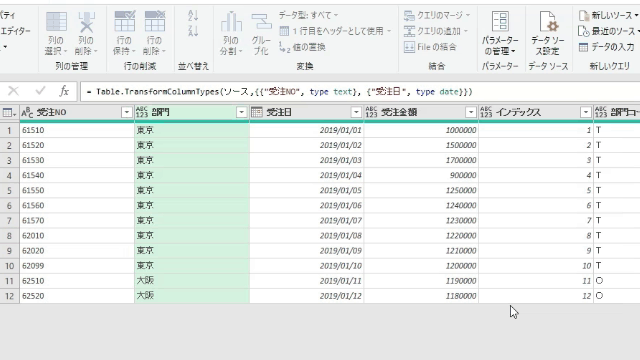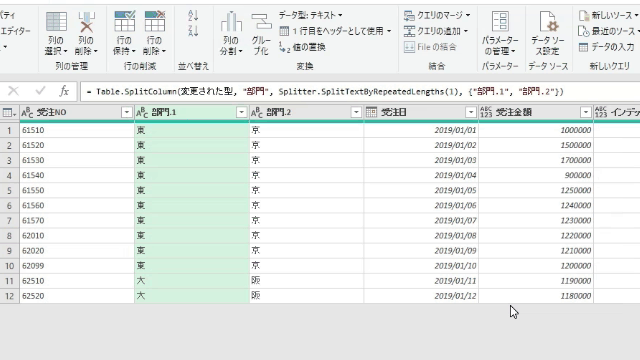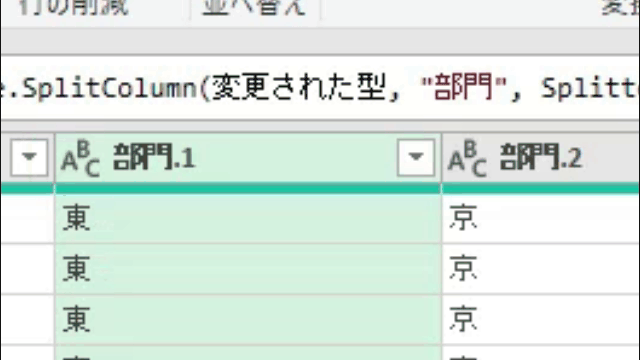
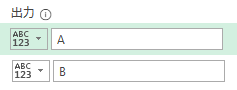
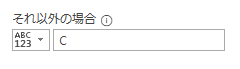
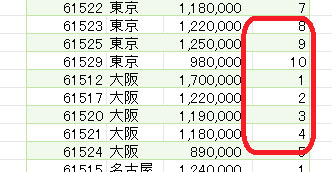
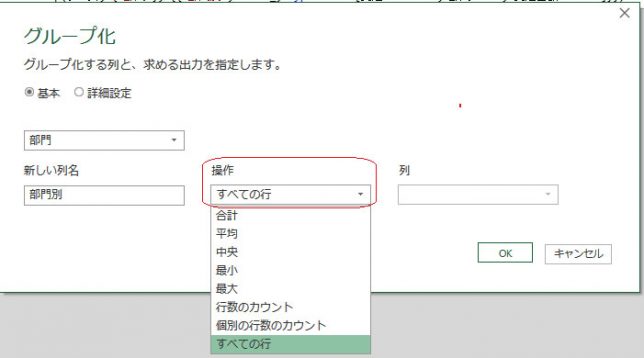
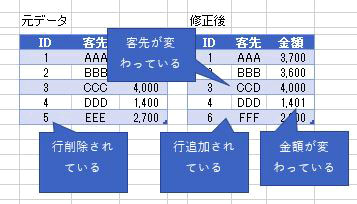
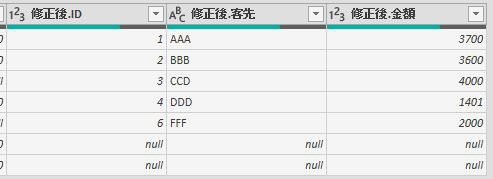
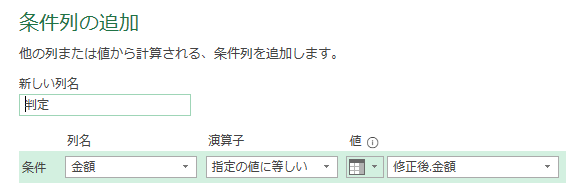
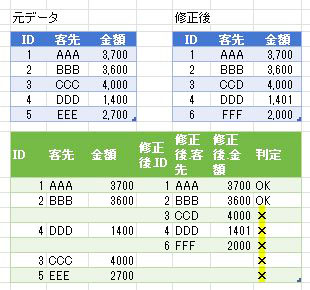
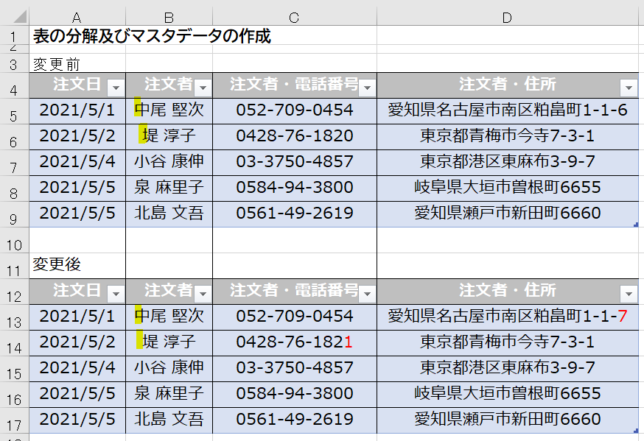
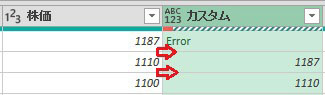
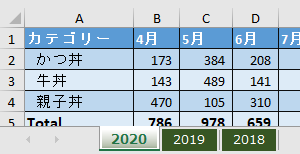
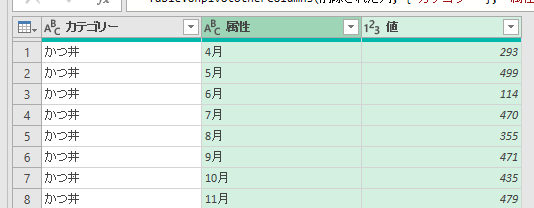
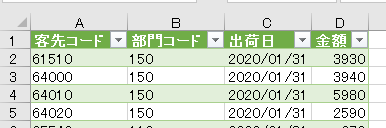
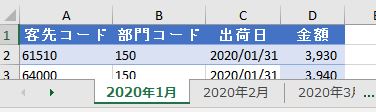
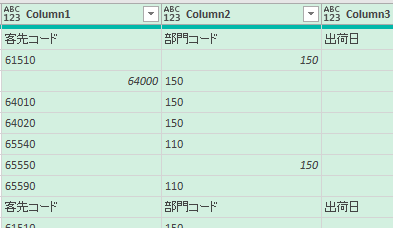
今回は上の画像のようにデータが複数シートに散らばっており、しかも行見出し位置/ヘッダー行が不規則なデータを一括で取得します
今回の最大のポイントは、List関数で行見出しの位置を取得する点です
そこさえクリアすれば、意外と簡単にできます
では、今回使用するデータと行いたい事の確認から解説を始めます
今回使用するデータと行いたい事
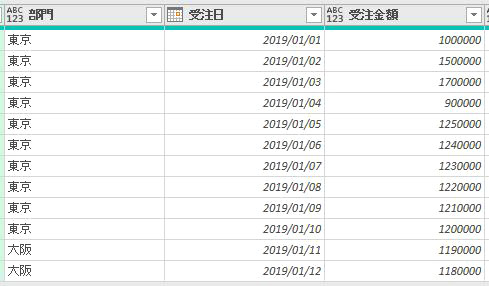
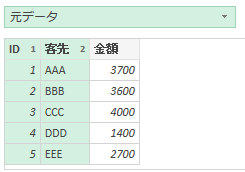
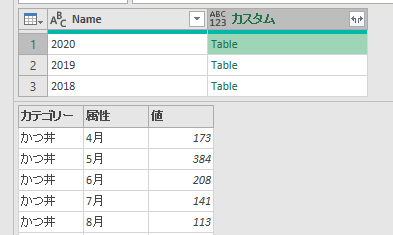
今回使用するのは次のファイルです
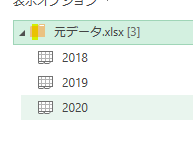
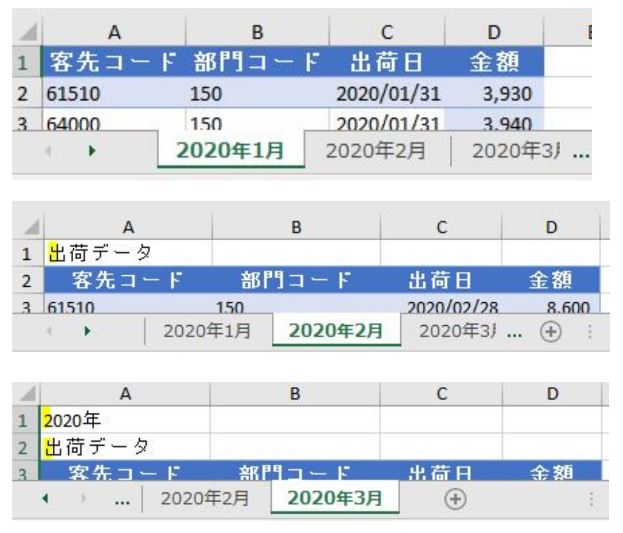
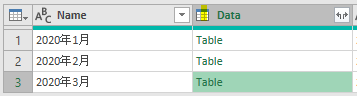
このファイルの中には3つのシートがあります
但し、前述のように3つのシートそれぞれの行見出し位置が違います
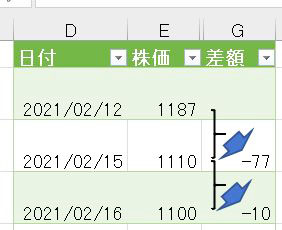
2020年1月のデータは1行目から始まっていますが、2月のデータは2行目から始まります
そして、3月のデータは3行目からです
この3つのシートからM関数を組み合わせてデータを一括で取得するのが、今回行いたい事です
今回のポイント
今回の最大のポイントは、前述のようにList関数で行見出し位置を取得することです
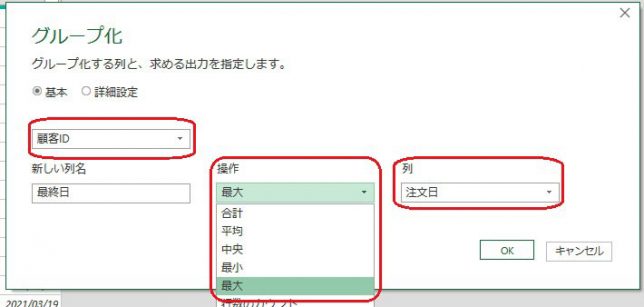
行見出し位置を取得するには、行見出しにある「客先コード」をキーにして、M関数「List.PositionOf」を使います
List.PositionOf関数の他にも2つM関数を組み合わせます
List.PositionOf
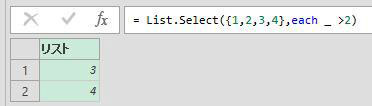
List.PositionOf関数はリストの中から、指定の値の位置を取得します
書き方は、次の通りとなります
List.PositionOf(リスト名,取得したい値)
ここで、注意点が1点あります
M言語は0ベースである点です
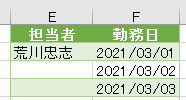
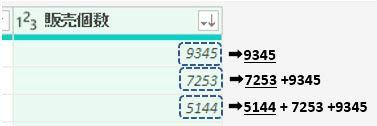
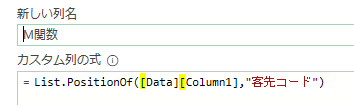
例えば、List.PositionOf関数を使用すると、次の画像の「客先コード」の位置は1ではなく「0」とでます
これは、M言語が0で始まる仕組みになっているからです
Table.RemoveFirstN
Table.RemoveFirstNは、テーブルから指定した行数を削除するM関数です
書き方は次のように書きます
Table.RemoveFirstN(テーブル名, 削除する行数)
Table.PromoteHeadersは、1行目を見出しに昇格させるM関数です
Power Queryエディタ内にも同じメニューがあります
今回の内容は、後述しますがM関数で行った方がベターです
このM関数の書き方は、次の通りとなります
Table.PromoteHeaders(テーブル名)
今回のポイントである、3つのM関数の内容を確認したところで、本格的な解説をはじめます
ファイルの読込
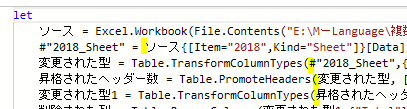
まず最初に、前述のサンプルファイルの読込処理を行います
サンプルファイルとは別のファイルで、下の画像の処理を行います
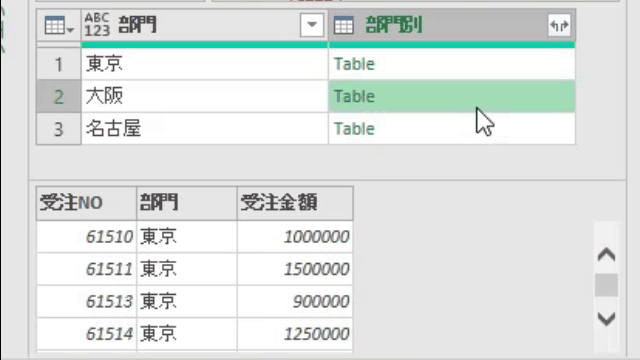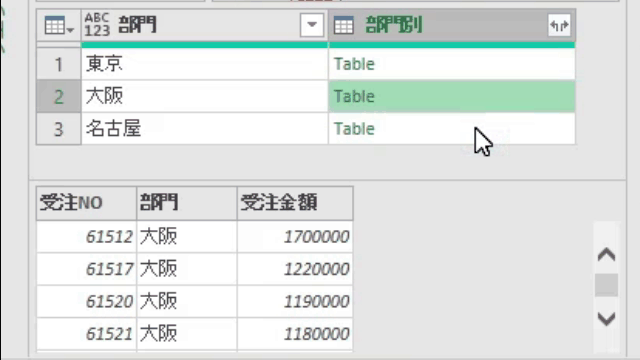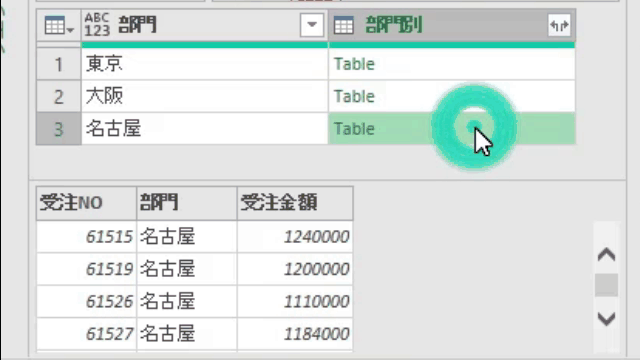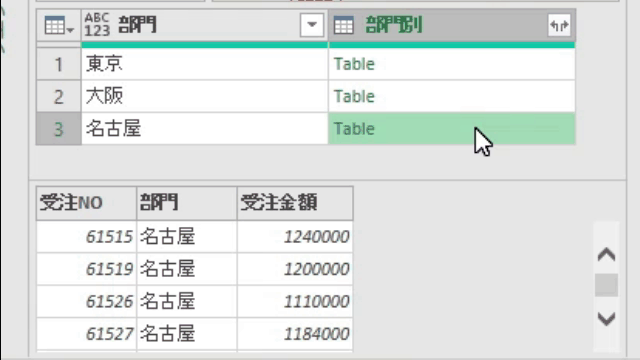
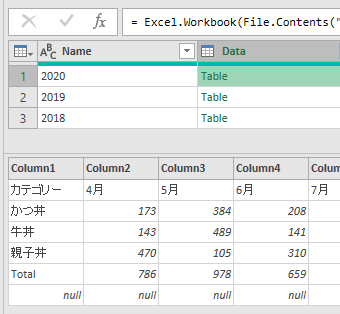
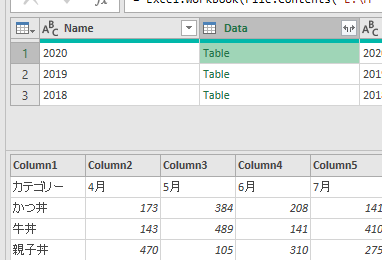
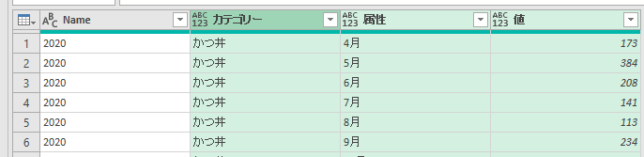
上の画面の「ブックから」で前述のサンプルファイルを指定した後、Power Queryエディタ(以降、エディタ)が開くと次の画像のような状態になっています
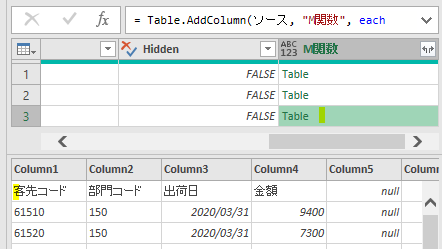
上の画像の左から2つ目の列にある「Data」が今回のポイントの一つです
各行にある「Table」の文字の横をクリックすると、次のGIF画像のように中味が見れます
次からはこの「Data」列を活用して、カスタム列をM関数により作成します
カスタム列の作成
List.PositionOf関数で行位置を抽出
では、カスタム列・作成画面を開きましょう
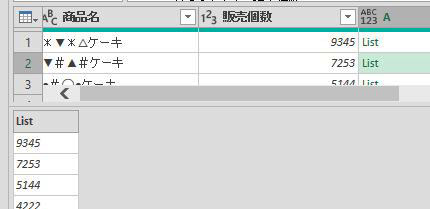
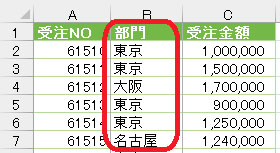
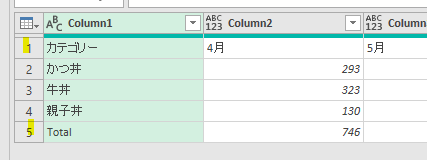
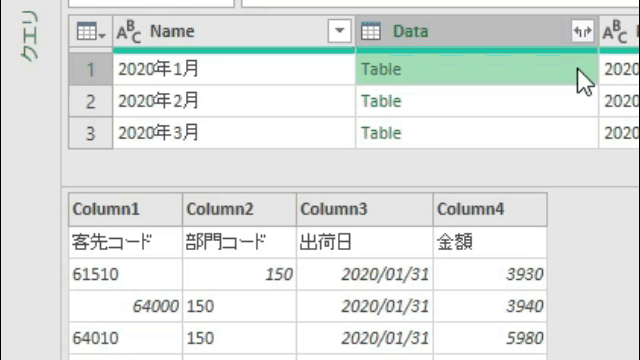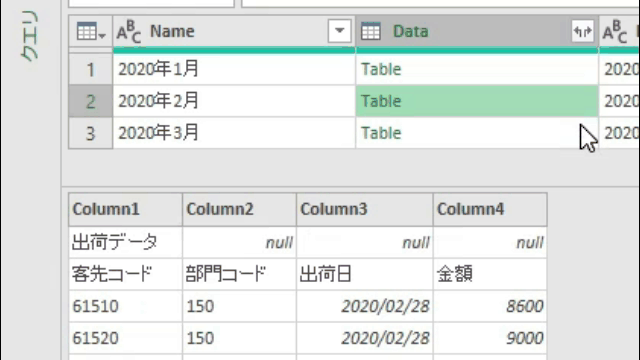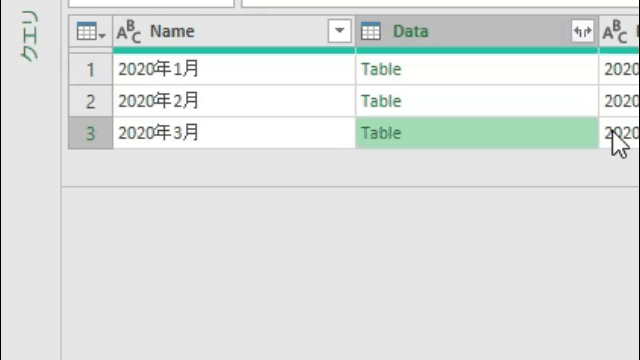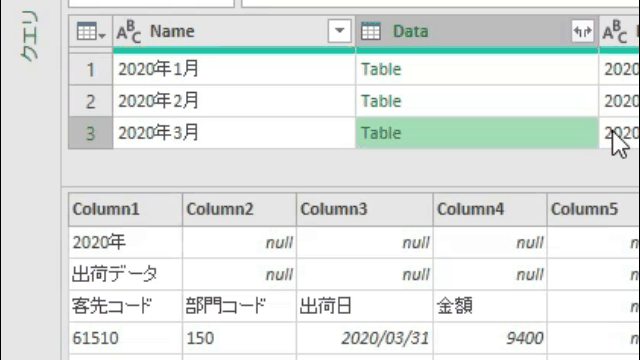
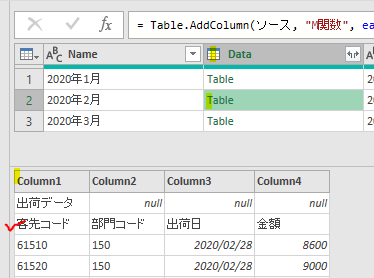
ここで確認ですが、行位置を取得する対象は下の画像の「客先コード」の文字です
上の画像を見ると、「客先コード」にはⅰ)Data/Table➡ⅱ)Column1➡ⅲ)客先コードの順で指定するとたどり着けるようになっています
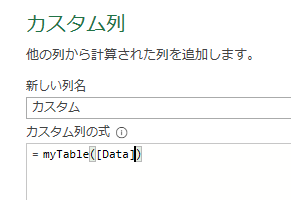
カスタム列・作成画面でも、M関数/List.PositionOfでの引数設定時に上の流れを使用して指定します
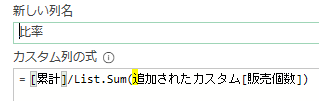
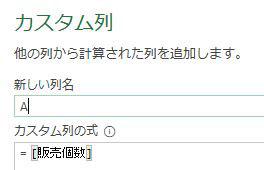
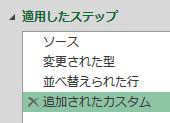
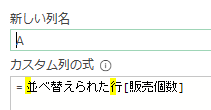
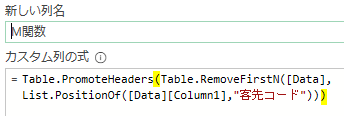
上の画像のようにList.PositionOf関数の引数を次の様に指定します
第一引数:[Data][Column1]
第二引数:”客先コード”
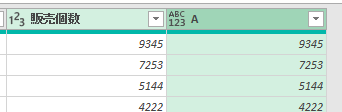
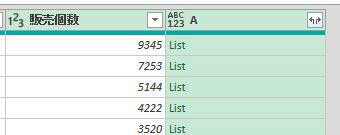
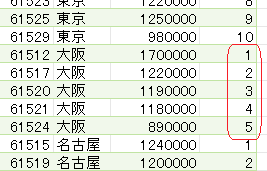
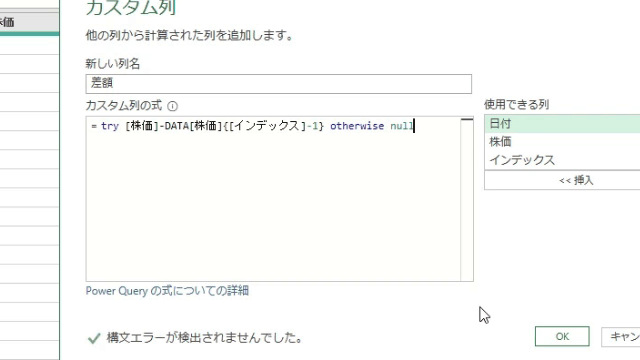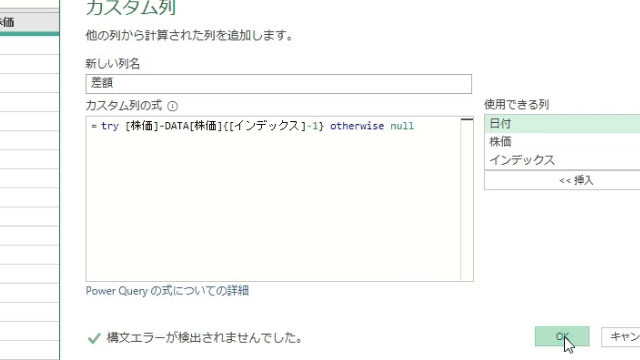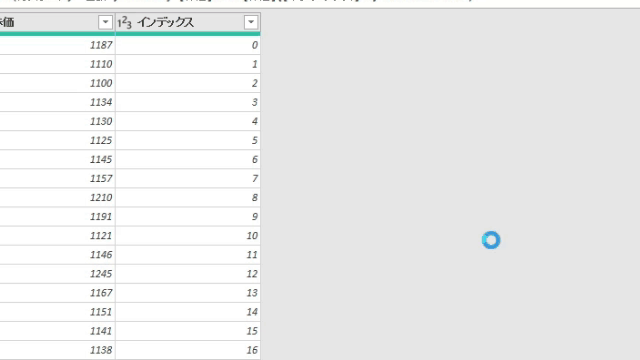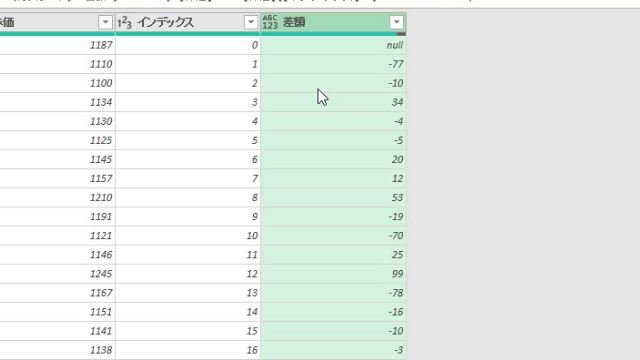
そして、カスタム列・作成画面の下にあるOKボタンを押すと次の画像のように客先コードの位置が出力されます
あくまでM言語は0から始まるので、その点についてはご注意ください
1行目の内容では、客先コードは1行目にありますがM言語のベースに従って0と出力されています
Table.RemoveFirstNで不要な行の削除
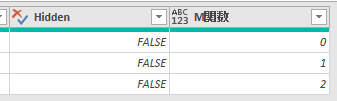
List.PositionOf関数により行見出しの位置は抽出できましたので、「行見出しの位置-1」分の行数をM関数/Table.RemoveFirstNを使用して削除します
Table.RemoveFirstN関数の書き方は、前述の通り次の通りです
Table.RemoveFirstN(テーブル名, 削除する行数)
今回は上の第一引数のテーブル名には、[Data]を入力します
そして、第二引数には上のList.PositionOf関数をー1をせずにそのまま設定します
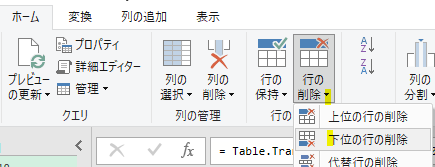
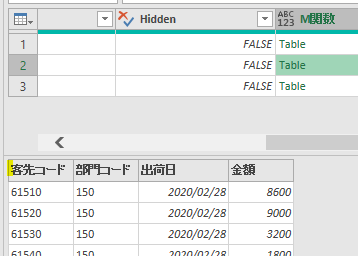
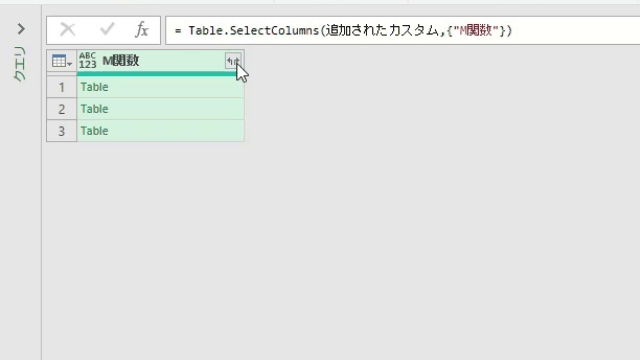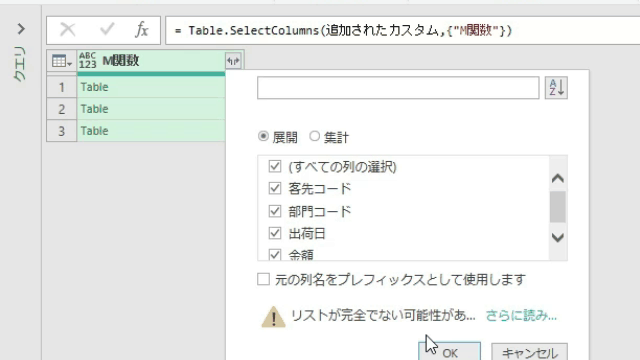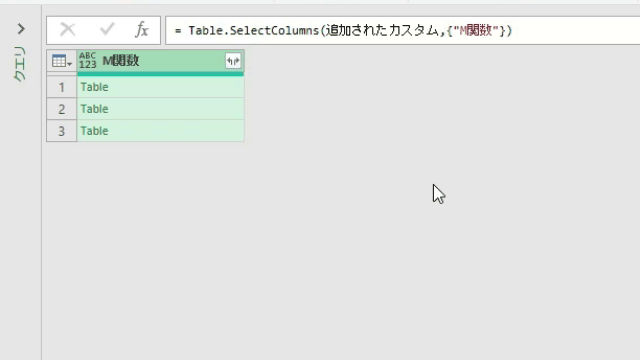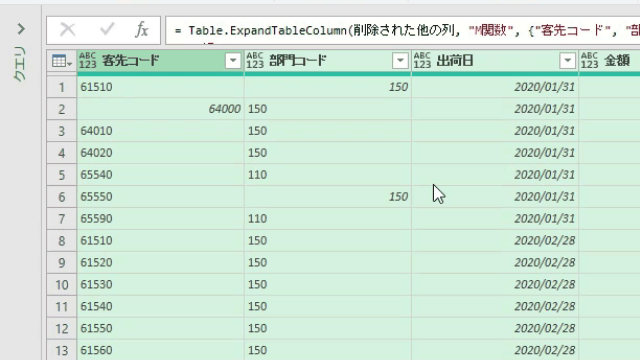
上の画像の通りに数式を指定してOKボタンを押すと、「本来、行見出しにするべき行/客先コードのある行」が次の画像のように1行目に来ています
但し、このまま作成されたテーブルを展開すると不都合な点が1点あります
本来、行見出しにするべき行が行見出し/ヘッダーになっていませんので、このまま展開作業をすると不要な行見出しがデータとして入り込んでしまいます
ですので、もう一つのM関数で不要な行を削除できるようにします
では、最後の仕上げとして各テーブルの1行目を見出し行/ヘッダーにします
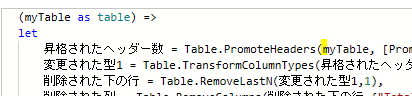
こちらは、M関数/Table.PromoteHeadersの()の中にこれまでの内容を入れるだけです
Table.PromoteHeaders関数の内容を反映した結果が次の画像です
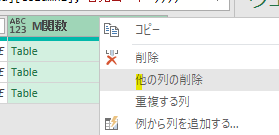
上の画像の内容で、各テーブルを展開処理すればいいのですが、その前に既存の列は削除しておきましょう
「他の列の削除」が終了したら、後は各テーブルを展開するだけ終了です
<まとめ>
今回は、List.PositionOf関数をはじめとする3つのM関数を組み合わせて、不規則なデータを一括で処理できるようにしました
最大のポイントは、不規則な行見出しの位置をM関数で取得する点です
それさえできれば、後は機械的にM関数を組み合わせるだけで一括処理ができるようになりました
今回の題材は、M関数の魅力、そしてM言語の魅力を知るのにいい題材だったと思います
ぜひ手を動かして体験してみてください
長文に最後までお付き合いいただきありがとうございました
参考までに、今回の内容の完成版のファイルを添付します


にほんブログ村